
Всем привет! Захотелось мне статистически сопоставить Стопгеймовские оценки игр с какими-нибудь большими данными — как они соотносятся? есть ли взаимозависимость? возможно ли вообще такое сделать?
Предлагаю вашему вниманию небольшое исследование, которое не ставило себе высоких целей и задач, а делалось в основном по приколу.
Подготовка данных или как не делать обезьянью работу
Для начала нужно собрать базу игр, с которой будем дальше развлекаться.
Информацию со странички с распределением всех обзоров на оценки нужно привести в скучный табличный вид. Итого 73 страницы, в среднем по 30 игр на каждой — это 2 190 игр. Положим, по две минуты на перепечатку названий вручную и отдых — это 73 часа!
Нужно что-то другое. В конце каждого заголовка с обзором написано «: Обзор», что и натолкнуло на мысль — можно открыть код страницы, скопировать его в эксель (выглядит ужасно, но больше я ничего не умею), и отфильтровать строки, где есть этот самый «: Обзор». Сказано — сделано. Каких-то жалких 40 минут спустя появилась база Стопгеймовских оценок.
Теперь надо найти то, с чем сравнивать оценки. На реддите обнаружился пост, в котором кто-то выложил огромный файл с базой рейтингов Game Rankings перед его закрытием (сам сайт теперь форвардит на Метакритик). Файл датирован декабрём 2019 г., так что полтора года новых игр придётся упустить.
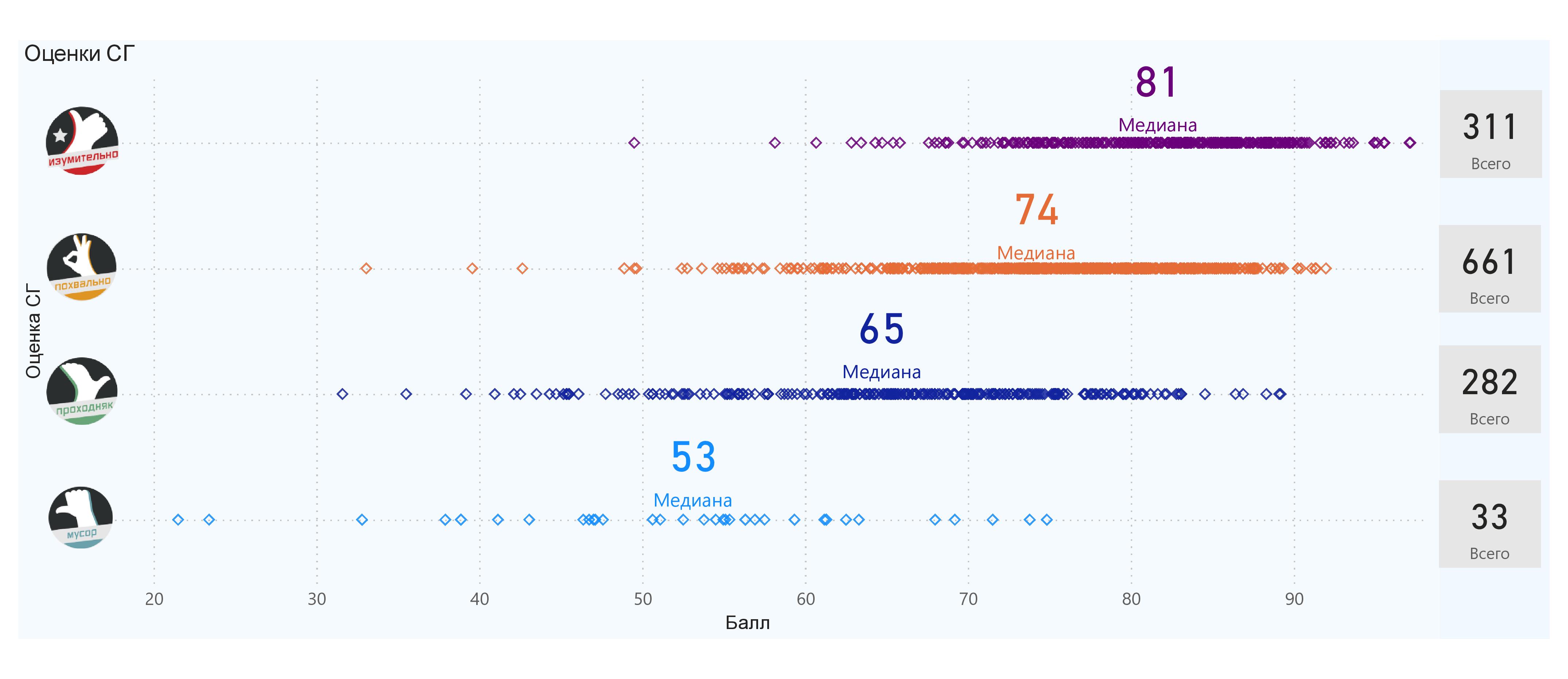
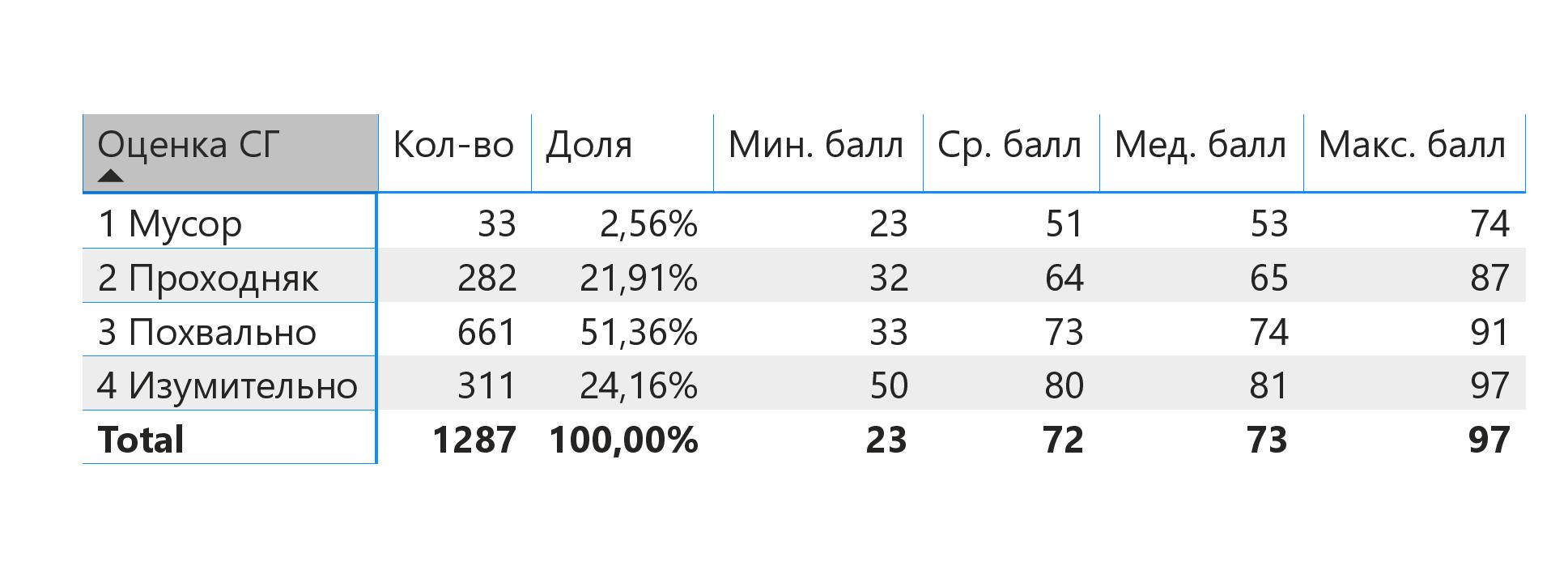
В итоге набралось 1 287 игр, выпущенных в 2010–2019 гг.
Моделирование (не 3D, а статистическое)
Для научно обоснованного подхода к анализу взаимосвязей используем мультиномиальную логистическую регрессию.
Регрессионный анализ исследует статистическую связь между одной зависимой переменной и (одной или несколькими) независимыми и показывает наличие или отсутствие связи, её силу, позволяет потом сделать прогноз одной из переменных, зная другие. Например, исследовав связь возраста игрока и часов, проведённых за компуктером в день, можно прикинуть количество часов для любого возраста вообще (конечно, с кучей нюансов, о которых не будем).
Самая распространённая регрессия — линейная, которая исследует связи между числовыми переменными. В нашем же случае исследуется зависимость между баллом игры и оценками СГ, которые нечисловые и могут быть лишь четырёх видов. Поэтому линейная регрессия нам не подходит, нам нужна логистическая, которая учитывает нечисловые переменные.
Загружаем нашу таблицу в статпакет и за жалкие какие-то 28 строчек кода получаем статистически значимую регрессию, которая провела анализ загруженной базы и выявила взаимозависимости между оценками СГ и баллами игр. Для наглядности я вывел модельную вероятность той или иной оценки СГ в зависимости от балла критиков.
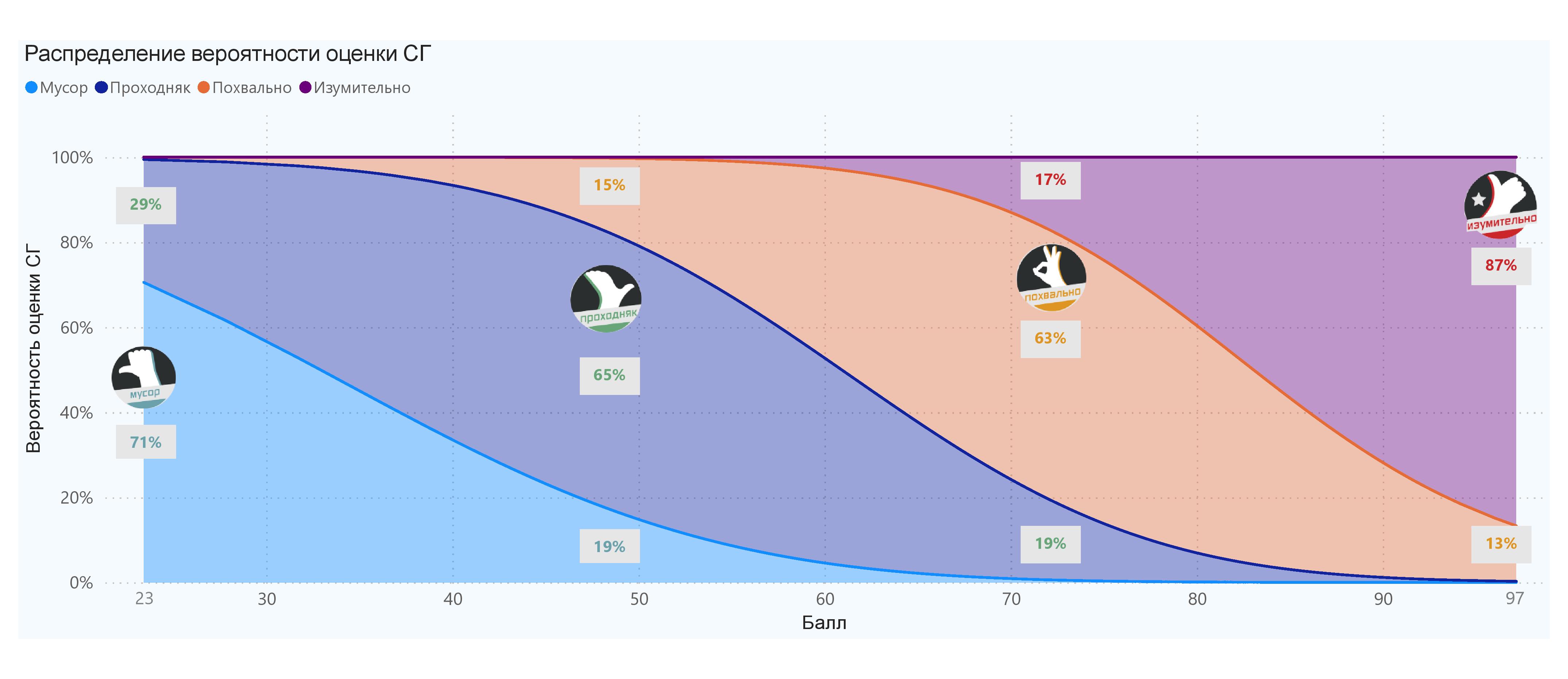
Выводы
- Есть положительная взаимосвязь между оценкой СГ и баллом игры — чем лучше оценка, тем выше средний балл (кто бы сомневался).
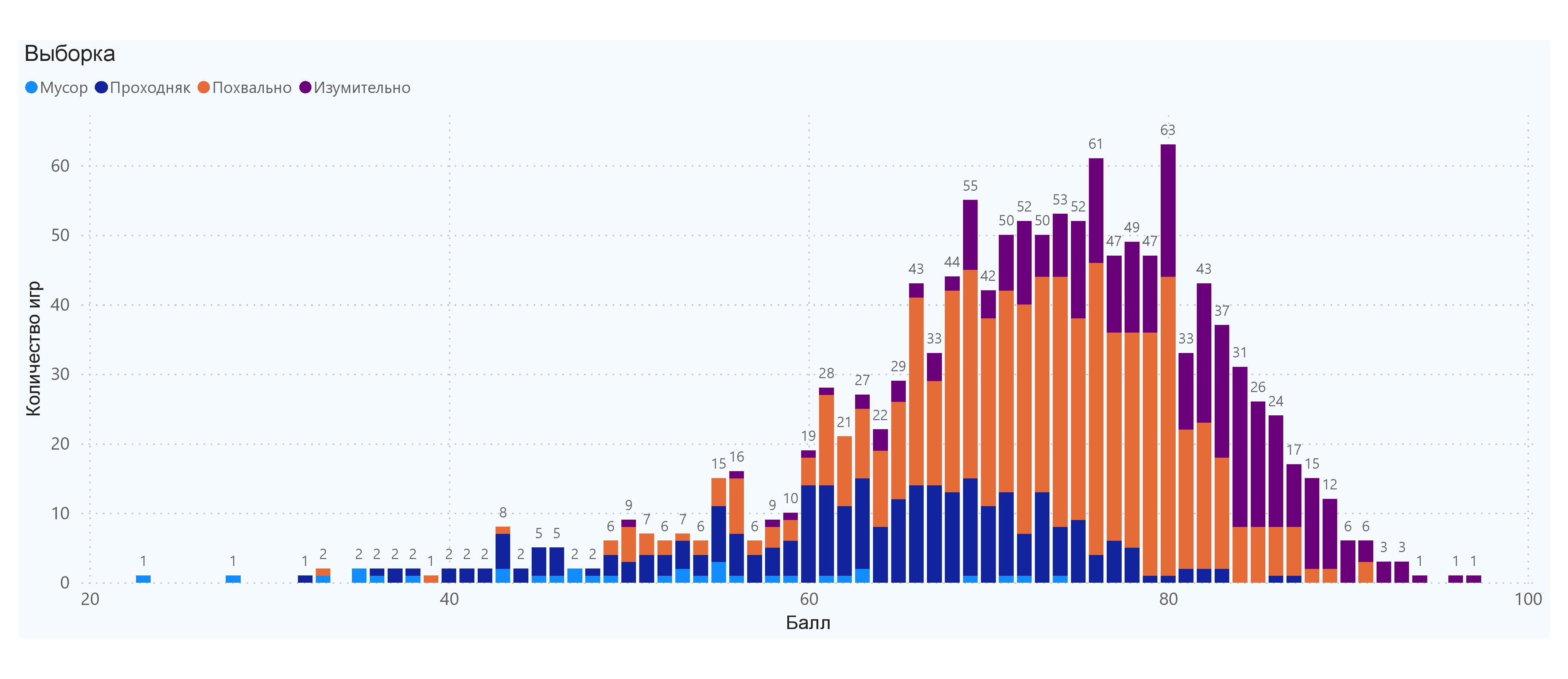
- В целом критики большинству игр присваивают баллы между 70 и 80. В этом диапазоне вероятность «Похвально» — 66%, «Изумительно» — 19%, «Проходняка» — 12%. То-то у нас так много «Похвальных» игр.
- И, мне кажется, самое интересное. Если считать, что «Мусор» и «Проходняк» — в целом «плохие» игры, а остальные — в целом «хорошие», то вероятность какой-либо неизвестной игры оказаться «плохой» — 51% (соответственно «хорошей» — 49%). Практически идеальный баланс объективности Стопгейма! Зато далее Стопгейм благоволит разработчикам — «плохая» получит «Мусор» с вероятностью 34%, а «хорошая» получит «Изумительно» с 41%.
Самое главное — оценки Стопгейма в массе своей хороши и мнение критиков с ними согласуется, почти что научно доказано :)
На этом пожалуй и всё. Спасибо, что были с нами, надеюсь, кому-то было интересно.
При исследовании использовались Excel, RStudio, Power BI, Chrome и чёрный чай.








Лучшие комментарии
Первый вроде как комментарий
Так потому что неизвестные )
А можно просто попросить Доттериана за пару минут любую статистику собрать напрямую из базы данных. :D
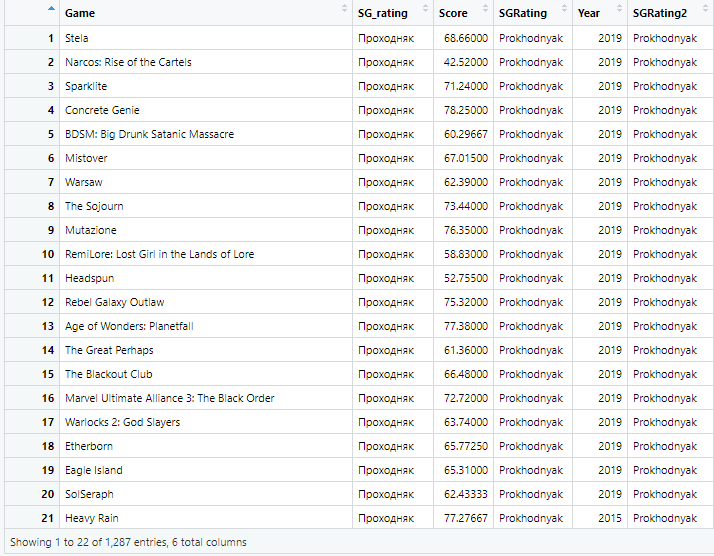
Что там за игра получила под 50 баллов и одновременно с этим изюм?)
Было бы интересно глянуть на всю выборку целиком, в гугл таблицах например.
P.S. За проделанную работу мое почтение, люблю ковыряться в цифрах)
У меня вот эта часть в статье вызвала больше всего вопросов. Я и так, и сяк, и эдак себе это пытался представить, но не понял, как можно целый ЧАС списывать названия игр и их оценки.
Две минуты — это на одну игру? о_О
(я щас буду «в воздух» озвучивать планы решения задачи по переносу инфы в таблицу)
Во-первых, если есть навык скоропечатания (или друг, обладающий оным), можно скооперироваться с другом и: он читает вслух тебе название игры и оценку, ты — записываешь. В таком случае ну по паре-тройке минут уходить будет на страницу. Причём если названия игр, очевидно, надо записывать полностью, то оценки запросто можно сокращать до «изюм», «похв», «прох», «мус» (но тут такая себе экономия в нажатиях, конечно). Ультимативно — «мусор» меняем на «1», «изюм» на «4».
Во-вторых, если навыка скоропечати нет, как и знания английского на должном уровне (чтобы избежать опечаток при вводе названий, потому что дальше ж их сравнивать придётся) — можно просто копипастить названия игр. И потом опять сокращать оценки.
Но даже если полностью писать названия и оценки, я не верю, что на каждую игру потребуется целых две минуты на заполнение двух граф «игра — оценка».
PS: А потратив немного больше времени можно было бы ещё записать авторов и провести статистику по ним, а не просто по оценкам! (но я не призываю к действию, еслишо, я понимаю, что даже в спидраннерских режимах заполнение такой базы пару часов-то запросто сожрёт)
Научно доказано — пятая оценка не нужна, спасибо, мы и так идеально объективны!
Вообще было бы интересно глянуть не только на медианы, но ещё и на какие-то пиковые точки (самые высоко оценённые игры, которые получили «мусор», которые получили «проходняк» и наоборот, игры с самыми низкими оценками, которые получили «похвально» и «изюм»).
Плюс, возможно, какой-нибудь небольшой разбор и мнение почему так могло получиться х)
По гистограмме таких игр в диапазоне 55-65 баллов не так уж и много — вершина массива правее после 70 баллов. Стоит ли вводить новую оценку для небольшого количества игр? Сейчас их можно условно разделить на скорее «плохие» и скорее «хорошие», с минимумом неопределённости. И если добавлять новые оценки — то когда вовремя остановиться?)
Но наблюдение очень интересное
Надо ещё учитывать, что обзоры идут не на все игры, а только на хорошие или хайповые. Значит мимо проходят хорошие неизвестные и треш, который никому не нужен. Это ведь тоже должно как-то влиять?
Проще попросить стату у меня :D
Можно ещё использовать версию для печати — она обычно даёт довольно простой для парсинга результат ну или старый добрый анализ сайта скриптами — когда данные надо собирать :)
Ну если в двух словах – допустим у нас база по 1 000 школьникам, где у нас инфа про возраст и часы за компом в день. Строим график, где откладываем точки, где по оси Х – возраст, по оси Y – часы. И видим, что чем больше возраст, тем больше часов (то есть у нас точки вытянуты такой змейкой). См. пример на картинке, по рандомно сгенерированным данным.
Пунктирная линия – это уравнение линейной регрессии, то есть уравнение, которое наилучшим образом подогнало линейную зависимость на основе змейки точек. Y – это часы, X – это возраст. Вот и получаем, что Y = 1,8003X – 14,926, то есть подставив возраст вместо X, можно получить прикидку количества часов.
А дальше пошли нюансы:
— Регрессия показывает просто, что есть связь между Х и Y. Это возраст влияет на часы? А может быть, мы живём в параллельной вселенной, и чем дольше ты просидел за компом, тем ты моложе (часы влияют на возраст). Причинно-следственную связь регрессией не доказать
— Вдруг количество часов за компом в реальности зависит не от возраста, а от класса, в котором учится школьник? Тогда надо строить новую регрессию, и смотреть, что получается. Из самой регрессии это понять не получится
— Всё зависит от данных, которые изначально загружены в модель. На примере с часами если подставить возраст 30 лет, то выйдет, что такой человек проведёт за компом 39 часов в день. Явно же бред)) Значит такую модель можно использовать для возрастов, например, до 18, а для других строить новую модель (может и не линейную)
Поэтому настоящие регрессии сопровождаются кучей тестов, проверок, гипотез, вероятностей, анализами значимостей, доверительными интервалами и прочей мишурой, доказывающей, что именно данная регрессия хороша и всё учтено
Вуаля база
Проще просто написать программку, которая сама пробежится по сайту и вытащит всю необходимую информацию оттуда, в любом удобном формате, тогда можно ещё кроме автора спокойно добавить оценку пользователей, жанр, разработчика и пытаться строить корреляции ещё и по этим данным х)
Ручная работа сейчас, в век технологий, которые могут её значительно упростить, если не совсем убрать необходимость в ней это уже как-то не очень х)
После IDDQD ты становишься Ринатом (и мир вылетает с синим экраном, ибо Ринат един и неделим)
На самом деле, если посмотреть на график, то можно понять, что у вас как раз таки проблемы с играми в диапазоне 55-65 баллов, которые примерно с одинаковой вероятностью, приближенной к 50% получают как «проходняк», так и «похвально», при том, что вот автор «проходняк» относит к плохой оценке, а «похвально» к хорошей. Так что возможно как раз таки и не помешал бы какой-нибудь «похвальняк» х)
Спасибо) Ссылка на игру прилагается
Выборку причешу, подумаю, куда выложить
Мерси, действительно, выходит, полученные вероятности применимы для игр, прошедших некий «отбор» для обозревания. Можно было бы посмотреть, что влияет на (не)попадание игры в обзор (те же рейтинги, платформы, что-то ещё), но это прям целое дело. Пока что кажется, что если добавить треш (у которого скорее всего низкий рейтинг), то станет точнее граница между мусором и проходняком. С хорошими неизвестными сложнее — надо смотреть, почему не попадают в обзор.
The Great Ace Attorney Chronicles: Обзор
07 августа 13
HighFleet: Обзор
29 июля 25 +9
Wildermyth: Обзор
05 июля 18
Chicory: A Colorful Tale: Обзор
22 июня 7
Griftlands: Обзор
20 июня 12 +2
Astalon: Tears of the Earth: Обзор
16 июня 20
Lacuna: Обзор
11 июня 5
The Legend of Heroes: Trails of Cold Steel 4: Обзор
30 апреля 102
Monster Hunter Rise: Обзор
27 марта 20
Kaze and the Wild Masks: Обзор
19 марта 5
Atelier Ryza 2: Lost Legends & the Secret Fairy: Обзор
13 февраля 21
Super Mario 3D World + Bowser's Fury: Обзор
10 февраля 9
Skul: The Hero Slayer: Обзор
03 февраля 25 +22
Cyber Shadow: Обзор
25 января 35
Hitman 3: Обзор
22 января 22
OMORI: Обзор
07 января 18 +15
Unto the End: Обзор
22 декабря 2020г. 10 +5
The Last Show of Mr. Chardish: Обзор
23 ноября 2020г. 9
Tetris Effect: Connected: Обзор
19 ноября 2020г. 7
Crown Trick: Обзор
05 ноября 2020г. 12
Disc Room: Обзор
22 октября 2020г. 6 +1
Genshin Impact: Обзор
12 октября 2020г. 122
Among Us: Обзор
05 октября 2020г. 43 +1
Star Renegades: Обзор
30 сентября 2020г. 8
Hades: Обзор
28 сентября 2020г. 169 +3
13 Sentinels: Aegis Rim: Обзор
27 сентября 2020г. 9
Spelunky 2: Обзор
19 сентября 2020г. 12 +11
Eternal Hope: Обзор
10 сентября 2020г. 7 +4
Inmost: Обзор
10 сентября 2020г. 16
Armello: Обзор
Потом просто обработать-причесать довольно шустро можно. Либо накидать тоже какой-нибудь скриптик, который автоматизирует этот процесс, после чего у тебя будет вкусни-сочни список игр с определённой оценкой, в котором ты точно никаких опечаток не допустишь. В любом случае, 73 — это ты дико загнул )
А что же это за «мусор» на 74 балла аж был? Это уже очень сильный разброс.