
Всем здорова на, уже сколько вот лет умирантщих блогах! И, давайте, что ли, начнем с предыстории создания этого поста.
Во время осеннего стрима СГ по Мафии 3 (да, это чтобы вы поняли, сколько этот текст лежал в долгом ящике) в чате Твича разгорелся небольшой срач, мол, искусственный интеллект в игре вообще деревянный, и сейчас-то, в 2к16-м, за такую халтуру уже розгами бить надо! Как аргумент в пользу последнего, само собой, приводился ИИ F.E.A.R., который за десять лет с момента выхода игры облобызали все кто только можно, а некоторые (здоров, Макс!) до сих пор считают, что более умных компьютерных противников с тех пор в играх так и не представили. Данное мнение я оспаривать даже не собирался, так как сам в каком-то степени его придерживаюсь, но в голове надоедливым комаром плотно засел следующие вопрос — а почему так, собственно?
Дело в том, что лично мне, в силу наличия определённых знакомых, так или иначе удавалось заглянуть за ширму различных аспектов игростроя, из-за чего, всё-таки, произошла определённая деформация сознания — так что на момент срача на том стриме, вариант «Да разрабы прост халтурят и бабло пилят, ёпт!» даже не рассматривался. Ну не бывает так в крупном геймдеве, ребят, серьёзно. Вернее, даже если и бывает, то не может это быть первостепенной причиной того, что за десятилетие никто не создал шутер от первого лица, противников в котором называли бы «Убийцами ИИ F.E.A.R.», или чего уж там — хотя-бы последователями. Значит, какая-либо причина кроется в самом способе, которым был реализован вышеупомянутый ИИ. Поэтому я начал копать...
… ну, как копать… исчерпывающий ответ был найден по первому же англоязычному запросу в гугле. Всё это время в интернете, в свободном доступе лежал доклад Джеффа Оркина — ведущего (и единственного, лол!) программиста искусственного интеллекта первой части F.E.A.R., с GDC 2006. Правда, на русском языке даже более сжатых статей в открытом доступе не нашлось. Что ж, всего лишь вечера пары недель, потраченные не на мемасики в ВК, и теперь это не так! Надеюсь, данная статья ответит на ваши вопросы не только в отношении F.E.A.R., но и в какой-то мере прояснит вам, почему сейчас в играх мы имеем то, что имеем. Приятного прочтения.
P.S. Несколько абзацев в тексте посвящены весьма профильным аспектам, поэтому, возможны надмозговости. Если же каким-то образом случилось так, что вы разбираетесь в теме и видите неточность — пишите, буду исправлять.
Три Состояния и План: ИИ F.E.A.R.
Джефф Оркин
Monolith Productions/M.I.T. Media Lab, Cognitive Machines Group
Если аудиторию GDC спросить о наиболее распространенных техниках реализации ИИ в играх, то, несомненно, двумя лидирующими ответами будут «Поиск А*» (А*) и «Конечный автомат» (Finite State Machines (FSM)). Практически каждая игра, имеющая в себе ИИ, использует определенную форму КА для контроля поведения персонажей и Поиск А* для планирования путей. F.E.A.R. также использует эти техники, но в нетрадиционном формате. КА для персонажей F.E.A.R. имеет всего два состояния, а Поиск А* используется не только для планирования путей, но и для планирования последовательностей действий. Этот документ фокусируется на применении на практике практического планирования, и F.E.A.R. взят в качестве наглядного образца. Акцент же будет на демонстрации того, как система планирования улучшила процесс разработки поведения персонажей в F.E.A.R.
Мы хотели чтобы F.E.A.R. стала игрой, переплёвывающей лучшие кинобоевики, где бои против ИИ, по напряженности будут сравнимы с мультиплеерным матчем против опытных игроков. Боты прячутся за укрытиями, ведут огонь вслепую, влетают в оконные проемы, засыпают игрока гранатами, переговариваются друг с другом, и так далее. Из-за этого довольно нелогично звучит тот факт, что весь наш конечный автомат состоит всего из трех состояний.

1: Крышесносные битвы в F.E.A.R.
Три Состояния.
Три состояния в нашем конечном автомате – это Goto, Animate и UseSmartObject. UseSmartObject – это деталь реализации наших систем в Monolith, и по сути, она является тем же состоянием Animate, но управляемой данными. Вместо того, чтобы отдельно указывать, какая анимация должна проигрываться, процесс определения нужной анимации производится через SmartObject в базе данных игры. Так что в рамках этого документа, можно условиться, что UseSmartObject – это то же самое Animate. А это значит только то, что на самом деле в нашей КА всего два состояния – Goto и Animate!
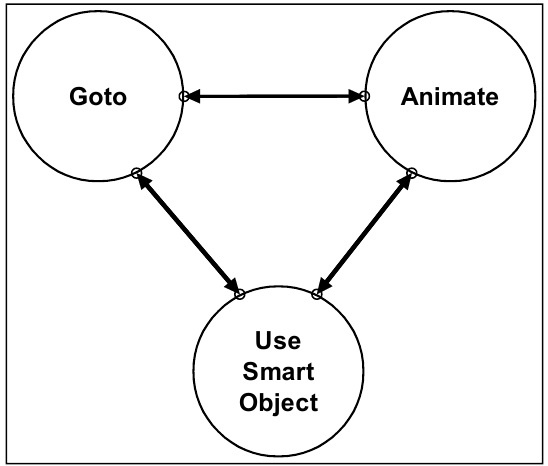
2: Конечный Автомат в F.E.A.R.
Поэтому, как бы нам не хотелось хлопать друг друга по плечу и разглагольствовать о нашем умном ИИ, реальность такова, что все, что делает наш ИИ – это двигается и воспроизводит анимации! Подумайте об этом. Когда ИИ бежит к укрытию, он просто двигается в нужную позицию, после чего воспроизводит анимацию пригибания или ползания. Когда ИИ атакует, то это просто зацикленная анимация стрельбы. Разумеется, есть в этом и детальные моменты: например, наша система анимации работает на ключах, в которые могут быть встроены сообщения, передающие звуковой системе, когда нужно воспроизвести звук шагов, или оружейной системе, когда нужно начать или прекратить стрельбу – но как только ИИ принял решение, он просто двигается и воспроизводит анимацию.
По факту и само движение происходит через проигрыш анимации! И даже другие различные анимации (такие как отдача, прыжки, падения) могут сдвинуть персонажа. Так что единственное различие между Goto и Animate состоит в том, что Goto воспроизводит анимацию лишь тогда, когда ИИ передвигается в какое-либо конкретное место, в то время как Animate просто проигрывает анимации, которые могут каким-то образом повлиять на положение персонажа в пространстве.
Загвоздка в моделировании поведения персонажа – это определение того, когда нужно переключаться между двумя состояниями, и какие параметры устанавливать. Как ИИ выбирает место, в которое должен побежать? Где это место? Какую анимацию при этом должен воспроизвести ИИ? Должна ли анимация проигрываться один раз, или быть зацикленной? Логика определения момента перехода из одного состояния в другое, и задаваемые при этом параметры – должны ли они быть вписаны непосредственно в C++-код этих состояний, или же могут находиться снаружи, в виде какой-либо таблицы или скриптового файла? Или же они могут быть представлены визуально, через какой-либо графический инструмент визуализации КА? В любом случае, логика, как обозначено, во всех этих случаях должна вручную задаваться программистом или дизайнером.
Управляемая комплексность.
В случае с F.E.A.R., именно здесь в дело вступает планирование. Мы решили перенести логику в систему планирования, а не внедрять ее в КА, как это было до этого. Как вы узнаете из этого документа, система планирования дает ИИ знание, которое открывает ему возможность самостоятельно решать, когда нужно переходить из одного состояния в другое. Это избавляет программистов или дизайнеров от бремени, которое растет с каждым новым поколением игр.
Во времена раннего поколения, например Shogo (1998), игрокам для счастья было предостаточно, если ИИ в принципе замечал их и начинал атаковать. Но в 2000-х аппетиты игроков выросли, что привело к тому, что ИИ научился занимать укрытия и даже создавать их, опрокидывая предметы интерьера. В No One Lives Forever (NOLF) 1 и 2, ИИ умел находить места, которые могут укрыть его от вражеского огня, а также высовываться из-за них, словно в тире-аттракционе. Сегодня же, игроки ожидают большего реализма, который мог бы дополнить реалистичную физику и освещение окружения. В F.E.A.R. ИИ использует укрытия с тактическим подходом и координируется с сослуживцами для организации подавляющего огня, позволяющего другим членам отряда обойти противника. Боты покидают укрытие только если их прижмут, и стреляют вслепую лишь тогда, когда не остается другого выбора.
С каждым таким уровнем реализма, поведение становится все более комплексным. И комплексность, которая требуется современным ААА-проектам, уже выходит за рамки управляемости. Доклад Дэмиена Ислы (Damian Isla) с GDC 2005, посвященный комплексности систем Halo 2 только подтверждает тот факт, что с этой проблемой сталкиваются все разработчики. Этот доклад можно рассматривать как вариацию на тему управления комплексностью. Внедрение планирования в режиме реального времени было нашей попыткой решить эту проблему.
И в этом и кроется один из главных выводов этой статьи: В F.E.A.R. нет ни одного частного элемента поведения, который нельзя было бы реализовать имеющимися техниками. Напротив, всё это – это комплекс комбинаций и слоёв всех поведений, который в итоге становится неуправляемым.
КА против Планирования.
Давайте сравним КА и планирование. КА диктует ИИ именно то, что ему нужно делать в каждой конкретной ситуации. Система планирования же, диктует ИИ его задачи и список доступных действий, позволяя ему самостоятельно решать, какую цепочку из этих действий нужно выстроить, чтобы достичь указанной цели. КА процедурный, в то время как планирование – декларативно. Позже мы рассмотрим, как можно совместно использовать оба эти типа систем так, чтобы они дополняли друг друга.
Мотивация исследовать возможности планирования пришла из того факта, что у нас был всего один программист искусственного интеллекта, но при этом очень много персонажей, обладающих этим самым искусственным интеллектом. Мысль была такова, что если нам удастся создать полноценный ИИ для этих ребят – то это будет просто отлично. Если мы хотим ввести поведение отряда, вдогонку к поведению каждого отдельного юнита, то это потребует больше человеко-часов на разработку – но если ИИ действительно будет столь умным, что сможет действовать сам по себе, то наша задача будет выполнена.
И прежде чем мы двинемся дальше, нужно полностью прояснить перед вами то, что мы подразумеваем под термином «планирование». Планирование – это формализованный процесс поиска последовательности действий, приводящих к выполнению поставленной задачи. Сам процесс планирования называется разработка плана. Система планирования, использующаяся в F.E.A.R., наиболее сильно походит на академическую систему планирования STRIPS.
Вкратце о STRIPS.
STRIPS был разработан в Стэндфордском Университете в 1970-м году, получив своё название от простого акронима – STandford Research Institute Problem Solver (Планировщик Решения Проблем Стэндфордского Университета). STRIPS состоял из задач и действий – задачи описывали желаемое состояние мира, которого мы хотели бы достичь, а действия показывались в виде предпосылок и последствий этому. Действие могло произойти, только если соблюдены все предпосылки, и каждое из них в какой-то мере изменяло состояние мира [Нильсон 1998, а также Рассел и Норвиг 2002].
Когда мы говорим о состоянии в контексте планирования, мы подразумеваем кое-что иное, нежели когда употребляем слово «состояние» в отношении КА. В контексте КА, мы говорим о процедурных состояниях, которые обновляют и приводят в действие код, принимающий и анимирующий решения; например, состояние Атака, или состояние Поиск. В системе планирования мы изображаем состояние мира как конъюкцию литералов – или, если иными словами, то мы изображаем состояние мира как заданный набор некоторых переменных, в совокупности описывающих этот мир.
Для примера, скажем, мы хотим описать состояние мира, в котором кто-то находится дома и надевает на себя галстук. В логическом выражении мы можем отобразить это вот так:
AtLocation(Home) ^ Wearing (Tie) / ВЛокации (Дома) ^ Надевает (Галстук)
Или же, задав вектор переменных значений. Тогда, это же будет выглядеть вот так:
(AtLocation, Wearing) = (Home, Tie) / (ВЛокации, Надевает) = (Дом, Галстук).
В другом же примере, если мы пытаемся отобразить состояние мира в игре Lemonade Stand, нам нужен вектор переменных, отслеживающий текущую погоду, количество имеющихся у нас лимонов и денег. В разное время, погода может быть солнечной или дождливой, а мы можем иметь различное количество лимонов и различное количество денег. При этом важно отметить, что некоторые из этих переменных имеют дискретный («солнечная» или «дождливая») набор возможных значений, в то время как другие – непрерывный (количество лимонов или же денег).
А теперь, давайте посмотрим на пример того, как же работает система планирования STRIPS. Допустим, Альма голодна. Альма может позвонить в Domino’s (международная сеть фаст-фудов) и заказать оттуда пиццу, но лишь при условии, что она знает телефонный номер Domino’s. При этом, пицца – не единственный для нее вариант. Она может испечь пирог, но лишь при условии, что она знает рецепт. То есть, у Альмы есть задача — достичь состояние мира, в котором она не голодна. На достижение этой задачи, у нее есть два действия — заказать пиццу, или испечь пирог. Если она в данный момент находится в состоянии мира, где у нее есть телефонный номер Domino’s, то она может продумать план заказа еды оттуда, чтобы удовлетворить голод. В качестве альтернативы же, если она находится в состоянии мира, где у нее есть рецепт, то она может испечь пирог. И если Альма находится в ситуации, когда у нее есть и номер и рецепт, то она может продумать план, который поможет ей решить задачу. Позже мы поговорим о том, как вынудить планировщика делать выбор в пользу одного плана перед другими. При этом, если у Альмы нет ни номера ни рецепта, то…ей не повезло. Нет реализуемого плана, который помог бы ей утолить голод.
Эти примеры показывают простой план с одним действием, но в реальности количество действий может быть каким угодно, а приводить к ним – различные предпосылки и последствия. Например, при заказе пиццы, должна быть выполнена предпосылка, что у Альмы достаточно денег для заказа, из-за чего, в случае несоблюдения предпосылки, цепочка плана может дополниться поездкой в банк.
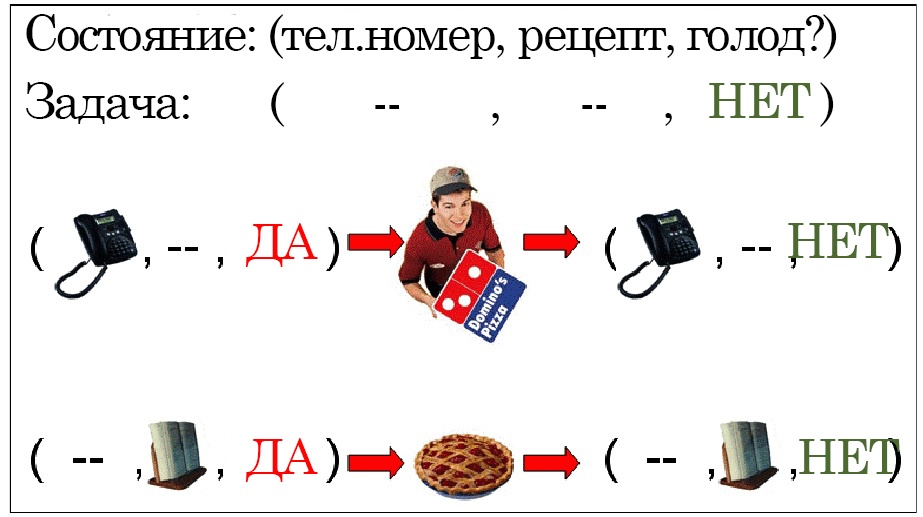
3: Два возможных плана для утоления голода в STRIPS.
Ранее мы уже рассмотрим задачу в STRIPS, как описание какое-либо состояния мира, которого хотелось бы достичь. А сейчас же, мы рассмотрим действие. Действие в STRIPS определяется предпосылками и последствиями. Предпосылки описывают состояние мира, точно так же, как и задача. Последствия же описывают список модификаций, привнесённых в это состояние мира. Так, последствие действия ЗаказПиццы во-первых, уберёт из списка «Добавить» факт, что Альма голодна, а во-вторых – привнесёт в список «Убрать» тот факт, что теперь Альма не голодна.
Может показаться странным, что мы удалили один факт (Голод), а затем добавили другой, а не просто поменяли переменную в одном и том же. Но так уж работает STRIPS, поскольку в формальной логике нет переменной, которую можно было бы ограничить всего одним значением. Если бы переменная Голод до этого была в состоянии ДА, и последствие действия ЗаказПиццы добавляло бы в переменную Голод факт НЕТ, то мы бы получили состояние мира, в котором ДА и НЕТ существовали бы одновременно. Можно представить себе действие, в котором и старались бы достигнуть подобного состояния. Например, действие Купить добавляло бы в состояние мира тот факт, что теперь у нас есть некий объект. Мы можем купить произвольное количество объектов, и наличие одного объекта не запрещает нам приобретать другой. Состояние мира в какой-то момент может стать таковым, что у нас будут монеты, ключ и меч.
Но, вернёмся к состоянию из прошлого примера – у нас есть два реализуемых планов того, как накормить Альму. Но что, если вместо нее, мы планируем ту же задачу для каннибала Пакстона Феттела? Ни один из этих двух планов, который бы удовлетворил голод Альмы, не подошел бы к кому-то, кто питается только человеченой! Нам нужно новое действие – СъестьЧеловека, чтобы удовлетворить Феттела. Теперь у нас есть три плана по утолению голода, но лишь два из них работают в случае с Альмой, и один в случае с Феттелом.
По сути, это и было тем, что мы сделали в F.E.A.R., но вместо планирования способов удовлетворения голода, мы планировали способы устранения угроз. Мы можем удовлетворить задачу устранения угрозы, если выстрелим в угрозу из оружия – но лишь при том условии, что оружие заряжено. Или же, мы можем ударить угрозу в ближнем бою, при условии, что мы достаточно близко. Таким образом, мы видим иной способ реализации модели поведения, уже реализованной нами ранее при помощи КА. Но в итоге…а в чем же суть? Легче всего можно понять преимущества этого решения с планированием, взглянув на то, как мы применяли эти техники при моделировании поведения персонажей в F.E.A.R.
Наглядный пример: Применение Планирования в F.E.A.R.
Философия дизайна в Monolith такова, что работой дизайнера является создание интересных пространств для проведения боёв, в которых может раскрываться ИИ. Например, пространства, заполненные различной мебелью, служащей укрытием; окнами сквозь которые можно прыгать и структурой архитектуры уровня, позволяющей заход с фланга. При этом, дизайнеры должны заботиться о прописывании поведения персонажей исключительно в сюжетных моментах — это означит, что во всех остальных моментах ИИ должен быть автономен в достижении поставленных им задач.
Если мы просто забросим ИИ на локацию в WorldEdit (наш редактор уровней), запустим игру и играя, попадём в его поле зрения….ИИ не сделает ничего. Ничего, потому что мы еще не поставили перед ним никаких задач. В этом же WorldEdit нам необходимо Назначать Задачи для каждого вида ИИ. При этом, задачи соревнуются между собой в приоритетности, и поэтому ИИ использует планировщик для выбора и решения наиболее приоритетной задачи.
В GDBEdit (нашем редакторе баз данных) мы создавали из этих задач Наборы. Для лучшего понимания, представьте себе, что мы создали набор под названием GDC06, который состоял всего из двух задач – Патрулировать и УбитьВрага. Когда мы зададим этот набор солдату в редакторе и запустим игру, тот уже не будет игнорировать игрока – отныне он патрулирует порт до тех пор, пока не увидит игрока, после чего он откроет по нему огонь.
Но если мы разместим на том же уровне Ассасина, задав ему тот же Набор Задач, то на выходе мы получим ощутимо иное поведение. Ассасин решает задачи Патрулировать и УбитьВрага в другой манере, нежели солдат. Он скрыто пробежит через всю карту, прыгнет на стену и прилипнет к ней, откуда слезет лишь при обнаружении игрока. Увидев его, ассасин спрыгнет со стены и устремится к игроку, размахивая кулаками.
И наконец, если мы разместим на тот же уровень простую крысу, и зададим ей набор задач GDC06, мы точно также увидим другое поведение. Крыса будет патрулировать уровень точно так же как и солдат, но вот атаковать никогда никого не решится. И следствием этого является то, что перед этими персонажами стоят одинаковые задачи, но для их решения они используют разные Наборы Действий. Набор Действий солдата включает себя действия для стрельбы из оружия, в то время как у Ассасина он состоит из ближнего боя и прыжков. У крысы же вообще нет возможности атаковать, поэтому она проваливает задачу УбитьВрага и просто возвращается к задаче с меньшим приоритетом – Патрулировать.

4: Три разных Набора Действий в GDBEdit.
Три Преимущества Планирования.
Предыдущий пример освещает лишь одно из трёх преимуществ использования системы планирования, а точнее– возможность разделять задачи и действия, что позволяет разным типам персонажей удовлетворять одни и те же задачи разными способами. Второе преимущество – возможность наслаивать простые системы поведения друг на друга, создавая видимость комплексной системы поведения. И третье – таким образом, расширяется спектр возможностей персонажа по решению проблем.
Преимущество №1: Разделение Задач и Действий.
В нашем предыдущем поколении систем ИИ, мы столкнулись в классическую для этой области проблему «Мимов и Мутантов». Это поколение использовалось в играх No One Lives Forever (NOLF2) и Tron 2.0. В NOLF2 были мимы, в то время как в Tron 2.0 – мутанты. Та версия ИИ, точно так же как и в F.E.A.R. сосредотачивалась на задачах, которые необходимо решать. Но при этом, там, в каждой задаче присутствовал встроенный КА. Там нельзя было отделить задачу от плана, который вёл к выполнению этой задачи. Если мы хотели добавить какую-либо вариативность в поведение мима или в поведение мутанта, или же между другими типами персонажей, нам приходилось добавлять ЕЩЁ ветки в, уже итак встроенные конечные автоматы. И в течении двух лет разработки, эти КА становились чрезмерно перегруженными, раздутыми, неуправляемыми и попросту рискованными в плане стабильности.
Например, у нас был каркас полицейского из NOLF2, который должен был останавливать вас, и переводить дыхание через каждые несколько секунд погони. Несмотря на то, что такое поведение требовалось привить всего одному типу персонажей, всё равно под него приходилось создавать целую ветку в конечном автомате для задачи Погоня, которая бы проверяла, не выдохся ли персонаж. С системой планирования, мы же можем задавать каждому персонажу их собственный Набор Действий, и в данном случае, только у полицейского будет действие для перевода дыхания. Уникальное поведение больше не добавляет ненужной комплексности другим персонажам.
Модульная природа задач и действий даёт свою пользу в F.E.A.R. тогда, когда мы решаем добавить новый тип врагов на поздней стадии разработки. Мы добавили летающих дронов с минимальными усилиями, просто скомбинировав задачи и действия уже имеющихся персонажей. Объединив действия призрака для перемещения по воздуху и действия солдата для стрельбы из оружия и использования тактических позиций, мы создали нового уникального врага с почти нулевыми затратами и полным отсутствием риска для существующих персонажей.
Есть также еще одна веская причина разделять цели и задачи – в нашей предыдущей системе, задачи, по сути были замкнутыми чёрными ящиками, и не обменивались информацией друг с другом. Это может приносить проблемы. Персонажей в NOLF2 окружали объекты окружения, с которыми они могли взаимодействовать. Например, кто-то мог сесть за стол и начать работать. Проблема была только в том, что задача Работать подразумевала, что ИИ находится в сидячем положении, взаимодействуя со столом. Когда мы убиваем этого персонажа, нам хочется, чтобы он, что и естественно, упал на стол — но вместо этого он закончит работать, встанет, задвинет стул, и лишь потом упадёт уже на пол. Так было потому, что между задачами не было никакого обмена информацией, из-за чего каждая задача должна была исполняться четко согласно указаниям и возвращать персонажа в исходное состояние, из которого он далее может приступить к выполнению следующей задачи. Разделение задач и действий вынуждает их обмениваться информацией относительно рабочего пространства. В разделённых системах, все задачи и действия имеют доступ ко всей информации, включая то, стоит ИИ или сидит, взаимодействует ли он со столом или другим предметом, и так далее. Мы можем учитывать эту информацию при составлении плана, удовлетворяющего задачу Смерть, из-за чего, труп упадёт на стол, как и задумывалось.
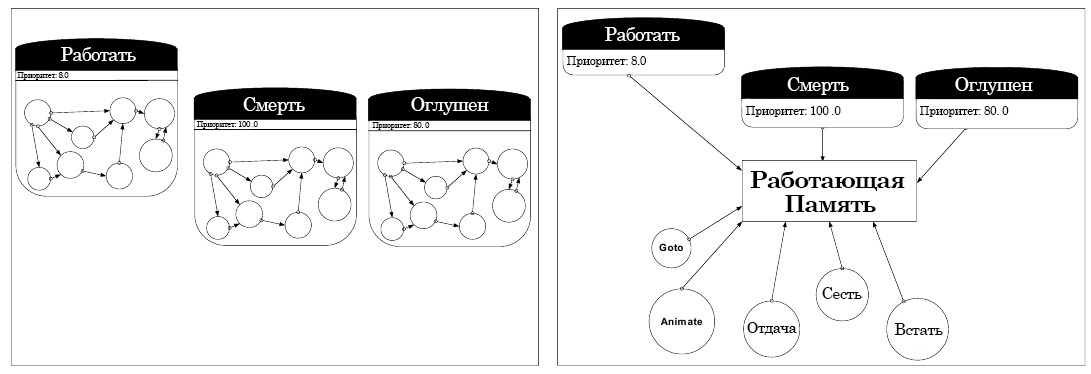
5: Черные ящики в NOLF2 (слева) и разделённые действия и задачи в F.E.A.R. (справа).
Преимущество №2: Наслаивание Поведений
Второе преимущество, открываемое планированием, предстаёт в виде возможности наслаивать различные типы поведения. Представьте, что обычное поведение солдата в бою состоит из семи таких слоёв. Мы добились глубокого, комплексного тактического поведения накладывая друг на друга более простые типы поведений. И мы хотели, чтобы у ИИ в F.E.A.R. на любое действие имелась причина, в отличии от NOLF2, в котором ИИ просто бежал до ближайшего укрытия и отстреливался оттуда, высовываясь из-за него в случайном порядке, словно в тире. В F.E.A.R. ИИ старается находиться в укрытии всё время, не покидая его до тех пор, пока не появится конкретная угроза и новое укрытие, в которое можно отступить – при этом ведение огня из-за укрытия производится им с максимально возможной эффективностью.
Начали же мы этот семислойный бургер с самых основ; с булочки: ИИ стреляет из оружия при обнаружении игрока. Они могут решить задачу УбитьВрага, используя для этого действие «Атака».
Мы хотели, чтобы ИИ ценил свою жизнь, поэтому следом добавили лист салата – при наведении на него оружия, ИИ пытается увернуться. Этот слой состоит из одной задач – Увернуться и, двух действий: УвернутьсяОтскочить и УвернутьсяПерекатиться.
Затем, следом пошла котлета – когда игрок подходит слишком близко, ИИ переключается с огнестрельного оружия на ближний бой. Этот слой требует на себя добавления всего одного нового действия, АтакаБлижнийБой, ведь у нас уже есть задача УбитьВрага, которому это действие вполне соответствует.
Если ИИ действительно дорожит своей жизнью, он не будет пытаться увернуться, а примет укрытие. Это сыр! Мы добавляем задачу Укрыться. ИИ же доставляет себя к укрытию через действие GotoNode, после чего действие УбитьВрага вновь становится вершиной приоритета. Находясь в укрытии, ИИ использует действие АтакаИзУкрытии, всё так же пытаясь решить задачу «УбитьВрага». Мы уже решили задачу с уворотом при помощи листа салата, но теперь мы хотим, чтобы ИИ пытался увернуться, при этом находясь в контексте укрытия, что потребовало от нас добавления еще одного действия – УвернутьсяВУкрытии.
Но уворот не всегда спасает, поэтому мы добавили помидор – стрельбу вслепую. Если враг получает ранение находясь в укрытии, он какое-то время начинает вести огонь вслепую, делая себя более сложной мишенью. И это, опять же, требует на себя добавления всего одного действия – СтрельбаВслепуюИзУкрытия.
И вот под самый соус появляются те вещи, где происходит вся магия. Мы даём ИИ возможность менять укрытие, если текущее становится ненадёжным. И это требует от нас простого добавления задачи Засада. Когда укрытие врага обнаруживают, он попытается спрятаться, используя ноду, обозначенную дизайнерами как Засада. Ну и наконец, пикули, которые добавляют нашему блюду аромат – в этот слой мы добавляем диалоги, чтобы не только игрок мог знать о чём думает ИИ, но и сам ИИ мог обмениваться информацией друг с другом. Но об этом мы поговорим позже.
Сейчас же важно то, что основная мысль, которую мы пытаемся донести в этой главе, заключается в том, что с системой планирования можно просто «накидать» задач и действий! Нам никогда не придётся вручную указывать переходы между этими слоями поведениями – искусственный интеллект сам, в реальном времени определяет приоритет задач, а также предпосылки и последствия своих действий.
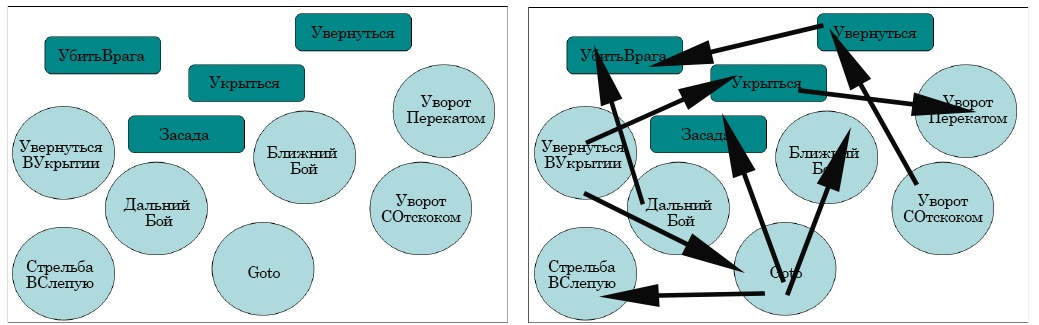
6: Мы занимаемся вот таким (слева). Но никогда не вот таким (справа).
На позднем этапе разработки NOLF2, мы добавили такое требование, что ИИ будет включать свет, когда заходит в тёмную комнату. В нашей старой системе, это требовало от нас вмешательства в конечный автомат каждой задачи и выяснения, как внедрить этот тип поведения. Это было не только головной болью, но и рискованной затеей, внедрять подобное на такой поздней стадии. С системой планирования F.E.A.R, реализовать это будет намного проще, ведь мы можем просто добавить действие ВключитьСвет с эффектом СветВключён, и добавив предпосылку СветВключён в действие Goto.
Преимущество №3: Динамическое Решение Проблем.
Третье преимущество системы планирования заключается в возможности ИИ динамически решать проблемы, путём перепланировки. Представьте себе сценарий, при котором у нас есть ИИ заходящий в дверной проход, видящий игрока и открывающий огонь. Если мы вновь запустим этот сценарий, но в этот раз игрок физически встанет перед дверью и заблокирует ее собой, то ИИ будет пытаться открыть ее и у него не получится. Но затем, он поменяет свой план и решит эту дверь выбить. Если и когда у него не получится и это, он постарается впрыгнуть в ближайшее окно, после чего сблизиться для рукопашной атаки!
Динамическое поведение возникает из этой самой перепланировки, производящейся с учётом знания о предыдущих провалах. Немного ранее, обговаривая разделение задач и действий, мы разобрали явный пример того, как в системе, работающей на основе взаимодействия, могут быть централизованы подобные знания. Когда ИИ, при попытке открыть дверь сталкивается с препятствием (дверь заблокирована) которое обрушивает его план, он может записать знание этого факта и учитывать его при перепланировке своих действий в поиске альтернативных решений задачи УбитьВрага.
Различия между системами планирования F.E.A.R. и STRIPS.
Теперь, когда мы увидели преимущества системы планирования в отношении работы над поведением персонажей, мы можем обсудить то, как же наша система отличается от упомянутой ранее STRIPS. Свою систему планирования мы описываем как «Задачно-Ориентированное Действенное Планирование» (Goal-Oriented Action Planning (GOAP) ), поскольку она была вдохновлена дискуссиями в GOAP-отделе Комиссии по Стандартам Интерфейсов И.И. (A.I. Interface Standards Committee (AIISC) ). Мы немного изменили её, для того чтобы эта система планирования была более практичной в контексте игры в реальном времени. Эти изменения сделали планировщик более эффективным и поддающимся контролю, но при этом не теряющим ранее описанных преимуществ. От STRIPS наша система отличается в четырёх аспектах – мы добавили «цену за действие», убрали списки «Добавить/Убрать» для последствий, а также добавили процедурные предпосылки и последствия [Оркин 2005, Оркин 2004, Оркин 2003]. Фундаментальная архитектура поддерживающая планирование была вдохновлена системой «С4», созданной отделом Synthetic Charachters в медиа-лаборатории М.Т.И., и описанная в их докладе на GDC 2001 [Бёрк, Исла, Дауни, Иванов и Блюмберг 2001], позднее более детально раскрытой в [Оркин 2005].
Отличие №1: Цена за действие.
Ранее мы говорили, что если у Альмы есть и номер телефона и рецепт, то любой из этих двух планов может помочь ей утолить голод. Если мы введём цену за действие, мы можем заставить Альму расставлять приоритеты и делать выбор в пользу одного действия перед другим. Например, действию ЗаказПиццы мы зададим цену в 2.0, а действию ИспечьПирог — цену в 8.0. Если она не сможет соблюсти все предпосылки для заказа пиццы, она может выбрать готовку пирога.
И вот здесь в дело вступает наш старый добрый друг – Поиск А*! Теперь, раз у нас есть мерило цены, мы можем использовать эту цену в качестве указателя для Поиска А*, чтобы тот выискивал наименее затратную последовательность действий, которая может привести к решению задачи. Обычно Поиск А* задействуется в контексте создания навигационного пути, и именно так мы и пользовались им в F.E.A.R. – чтобы прокладывать путь через навмеш (navigation mesh). Причем, по факту, Поиск А* — это действительно рядовой алгоритм поиска. А* может использоваться для поиска кратчайшего пути в любом графе узлов, соединённых гранями. В отношении навигации, интуитивно можно представлять полигоны навмеша как узлы, а грани полигонов – как грани графов, соединяющих один узел с другим. В отношении планирования, узлы представляют собой состояние мира, а мы ведём поиск с целью найти путь к решению задачи. Грани, соединяющие различные состояния мира – это действия, которые ведут к переходу мира из одного состояния в другое. Таким образом, в F.E.A.R. мы используем А* как для навигации, так и для планирования, и в каждом случае мы ведём поиск в совершенно разных структурах данных. Тем не менее, есть ситуации, в которых мы задействуем и то и другое. Например, когда ИИ проползает под препятствием, мы первым делом ищем навигационный путь, и лишь затем уже план, который позволит ИИ преодолеть препятствие по этому пути.
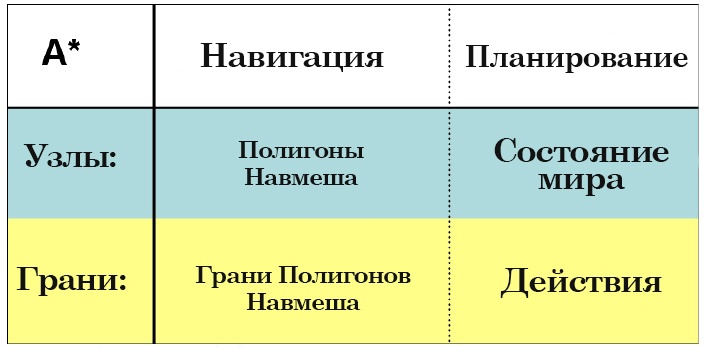
7: Сравнение А*, применённого к навигации и планированию.
Отличие №2: Отсутствие списков «Добавить/Убрать».
Нашей следующей модификацией STRIPS было удаление списков «Добавить» и «Убрать» при назначении последствий действий. Вместо того, чтобы описывать последствия так, как мы делали это ранее с этими списками, мы выбрали отображение и предпосылок и последствий одновременно, в фиксированном по размеру массиве, отражающим состояние мира. Это делает тривиальной задачей поиск действия, которое приведёт к последствию, удовлетворяющему задачу или какую-либо другую предпосылку. Например, действие Атака в качестве предпосылки имеет заряженное оружие, а действие Перезарядка это самое заряженное оружие имеет в качестве последствия. Таким образом, нам просто видеть, как эти действия образуют цепочку.
Наши состояния мира состоят из массивов с четырёхбайтными значениями. Вот несколько примеров используемых нам типов переменных:
ЦельМертва [bool]
ОружиеЗаряжено [bool]
ВТранспорте [enum]
ВУзле [HANDLE] или [variable*]
Две версии в переменной ВУзле обозначают, что некоторые переменные могут иметь как константное, так и переменное значение. Переменное значение является указателем на значение в родительской задаче, или же на предпосылку действия, в массиве состояния мира. К примеру, действие Goto может удовлетворить задачу Укрыться, позволяя ИИ прибыть в выбранный узел укрытия. Задача Укрыться же определяет, к какому узлу в массиве применяется Goto, отображая желаемое состояние мира.
Впрочем, фиксированный размер массива нас всё-таки ограничивает. В то время как у ИИ может быть насколько видов оружия и несколько целей, он может думать лишь об одном из них во время планирования, поскольку массив состояния мира обладает лишь одним слотом под каждое. Чтобы справиться с этим, мы использовали подсистемы избрания уже вне планировщика. Системы выбора целей и оружия определяют, какое оружие и враг в фокусе в данный момент, и планировщику нужно лишь согласоваться с ними.
Отличие №3: Процедурные Предпосылки.
Отображать всё, что нам нужно знать о целом игровом мире в фиксированном массиве переменных – это не практично. Поэтому, мы добавили возможность процедурной проверки предпосылок. В F.E.A.R., действие представляет собою класс С++, в котором предпосылки представлены и в виде массива переменных состояния мира, и в качестве функции, которая может проводить дополнительную фильтрацию. Так, ИИ, пытающийся избежать угрозы, может убежать, если он найдёт путь в безопасное место, или же просто пригнуться, если не найдёт. Функция «убежать» предпочтительнее, но может быть задействована лишь при условии, что функция ПроверкаПроцедурныхПредпосылок даст на это добро, проведя поиск безопасного пути по навмешу. При этом, было бы нецелесообразно постоянно просчитывать наличие путей к отступлению, ведь процесс поиска пути – ресурсоёмок. А функция процедурных предпосылок же, позволяет нам делать подобные просчёты лишь тогда, когда это необходимо.
Отличие №4: Процедурные Последствия.
По подобию процедурных предпосылок, нашим последним отличием от STRIPS стали также процедурные последствия. Мы не хотим просто напрямую применять эти последствия, ранее обозначенными нами как переменные состояния мира, поскольку мир будет реагировать на эти изменения мгновенно. В реальности же, передвижение в укрытие или уничтожение угрозы требует некоторого времени. Это именно то место, где система планирования подключается к КА. Когда мы приводим в действие наш план, мы последовательно активируем действия, которые свою очередь изменяют текущее состояние мира и все связанные с этим параметры.
Код внутри функции АктивироватьДействие() помещает ИИ в какое-либо состояние и задаёт какие-либо параметры. Например, действие Удирать помещает ИИ в состояние «Goto» и указывает какую-то точку прибытия для этого бега. Наш С++ класс для действий выглядит примерно следующим образом:
класс Действие
{
//Символические предпосылки и последствия
//выраженные в виде массивов из переменных.
СОСТОЯНИЕ_МИРА m_Предпосылки
СОСТОЯНИЕ_МИРА m_Последствия
//Процедурные предпосылки
Bool ПроверкаПроцедурныхПредпосылок();
Void АктивироватьДействие();
};
Поведение Отряда.
Теперь, когда ИИ достаточно умён для того, чтобы постоять за себя, программисты и дизайнеры искусственного интеллекта могут сосредоточиться на поведении отрядов. В F.E.A.R. у нас есть глобальный координатор, который периодически формирует из нескольких ботов отряд, основанный на дальности расположения солдат. В любой момент времени, каждый из этих отрядов может задействовать либо ноль, либо один вариант отрядного поведения. Отрядное поведение делится на две категории – простое поведение и сложное. Простое поведение включает в себя поддержку подавляющим огнём, отправку ботов по различным позициям, или же следование друг за другом. Сложное же поведение подразумевает под собой вещи, требующие более детального анализа ситуации, например обход с фланга, координированные атаки, отступления и запросы (и, соответственно, организация) подкреплений.
Простое Поведение Отряда.
У нас есть четыре типа просто поведения. Бежать-в-Укрытие даёт установку всем бойцам отряда, что ещё не находятся в хорошем укрытии, бежать в это самое хорошее укрытие, в то время как один из членов отряда осуществляет огневое прикрытие. Продвинутое-Укрытие делает то же самое, но бойцы занимают укрытия в непосредственной близости с угрозой. Продвинутые-Порядки перемещают бойцов по позициям так, что каждый следующий боец в цепи прикрывает следующего, а последний – осуществляет прикрытие со спины. И Поиск разделяет отряд на пары, которые прикрывают друг друга, при этом ведя систематический обыск помещений.
Простое отрядное поведение проходит четыре шага: первым делом, отрядное поведение пытается найти ИИ, которых можно будет поместить в требуемые слоты. Если таковые найдутся, отрядное поведение активируется и начинает раздавать членам отряда приказы. У ИИ в списке задач появляется следование этим приказам, но следовать им, или же решать более приоритетные задачи, выбирает сам ИИ. Например, спасение бегством может стать более приоритетным, нежели текущий приказ. Выполнение приказа для каждого ИИ отслеживается на отдельной таблице – но, так или иначе, ИИ либо выполнит приказ, либо не сможет в силу смерти, или еще какой-либо помехи.
Давайте рассмотрим в качестве примера элемент простого поведения Бежать-в-Укрытие. Скажем, у нас есть несколько ИИ, выкуривающих игрока из укрытия. Если игрок открывает огонь по одному из ботов и делает его укрытие ненадёжным, то может активироваться отрядное поведение. Так, если оно сможет найти бойцов, которых можно поместить в следующие слоты – одного для ведения прикрывающего огня, и одного, или больше для перемещения в укрытие. Обратите внимание на то, что поведению отряда не надо анализировать карту и просчитывать наличие доступных укрытий, ведь у самого ИИ есть сенсоры, хранящие данные о потенциально пригодных укрытиях неподалёку. Всё что нужно сделать поведению отряда – это выбрать один из известных ИИ узлов, и отдать приказ задействовать этот узел. Так, когда узел выбран, поведение отряда отдаёт приказ одному ИИ вести огонь на подавление, а остальным приказывает бежать в пригодные укрытия. ИИ же делает переоценку своих задач, и решает, что задача с наивысшим приоритетом – это следование поступившему приказу. Затем, поведение отряда следит за процессом следования, и если ИИ выполнил приказ, занявши укрытие, то поведение отряда сработало успешно. С другой стороны, если же игрок бросил гранату, уничтожив новое выбранное укрытие, ИИ может снова сделать переоценку задач и решить, что спасение бегством более приоритетно, нежели следование приказу. В данном случае, ИИ убегает в какое-либо незапланированное место, вследствие чего, работу поведения отряда можно считать неудавшейся.
Комплексное Поведение Отряда.
Теперь же, давайте посмотрим на созданное нами комплексное поведение. И, правда такова, что мы не создавали никакого комплексного поведения в F.E.A.R. вообще. Динамические ситуации возникают, как следствие разных уровней взаимодействия простого отрядного поведения и принятия решений каждого ИИ в отдельности, что создает ощущение наличия действительно комплексного отрядного поведения!
Представьте ситуацию, близкую к той, что мы рассмотрели ранее, когда игрок обстрелял укрытие ИИ, и отрядное поведение раздаёт приказ передислоцироваться. Если на пути ИИ при выполнении этого приказа возникнет какое-либо препятствие (например, сплошная стена), то он может просто развернуться и пойти обратно навстречу игроку. Из-за этого кажется, что ИИ обходит игрока с фланга, но на деле же, это просто побочный эффект следования в единственное доступное ему укрытие!
При другом раскладе, может укрытие ИИ и подошло бы ему, но если на локации присутствуют укрытия поближе к игроку, то отрядное поведение может активировать тип «Продвинутое-Укрытие», из-за чего ИИ начнет перемещаться в укрытие, более близкое к угрозе. Если между игроком и ИИ в этот момент находятся стены или другие препятствия, солдаты могут обходить их разными путями – таким образом, кажется, что ИИ скоординировались и пытаются взять игрока в клещи, в то время как они просто-напросто перемещаются в укрытие по разные стороны от игрока. К слову, отступление противника работает по схожему принципу.
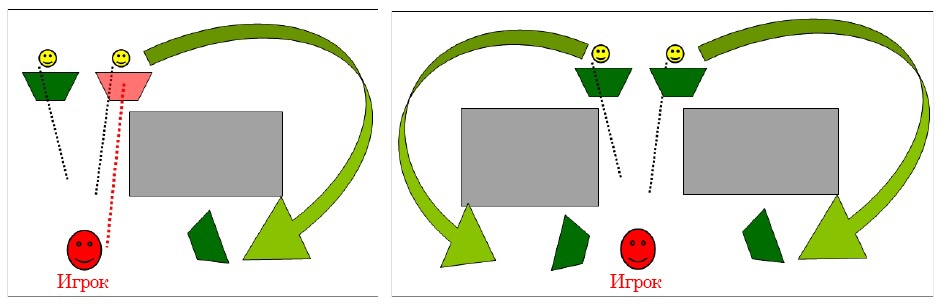
8: Комплексное поведение отряда, возникающее из текущей ситуации.
Реализация Отрядного Поведения.
Идея нашего отрядного поведения был вдохновлёна документом «Social Activities: Implementing Wittgnstein» за авторством Эванса и Барнета на GDC 2002. Сама же наша реализация отрядного поведения не выделялась ничем особенным – мы просто использовали формализованную STRIPS-подобную систему планирования для создания поведения отдельных персонажей, и просто дополнили её ровно настолько, насколько нужно было для работоспособности отрядного поведения в нашем конкретном случае. Можно даже сказать, что само разделение планирования на планирование отдельных персонажей и планирование отрядов гораздо важнее, чем какие бы то ни было способы реализации этого.
Следующим логичным шагом, который стоило бы совершить для F.E.A.R., было бы применение формализованной системы планирования к отрядному поведению. Разработчику, заинтересованный в планировании для отрядов, стоит взглянуть на Иерархическое Сетевое Планирование задач (Hierarchical Task Network planning (HTN) ), ведь там облегчено планирование возникающих параллельных действий, по сравнению со STRIPS [Рассел и Норвиг 2002] – а планирование для отряда, состоящего из отдельных ИИ, требует параллельного планирования нескольких задач одновременно. Система планирования HTN была успешно применена для координации ботов в Unreal Tournament [Муньос-Авильа и Хоанг 2006, Хоанг, Ли-Урбан и Муньос-Авилья 2005, Муньос-Авилья и Фишер 2004].
Отрядная Коммуникация.
Нет никакого смысла тратить так много времени и сил на реализацию отрядного поведения, если итоговый результат взаимодействия ИИ не будет очевиден для игрока. Слой отрядного поведения даёт нам возможность взглянуть на всю ситуацию с высоты птичьего полёта, где мы можем видеть всех одновременно, и выбирать соответствующие диалоговые конструкции. Из-за того что ИИ переговаривается друг с другом, игрок ощущает тот факт, что координация противника намеренная.
Причем иногда, для создания такого ощущения, вполне может хватить и просто вокализации – даже не обязательно, чтобы существовала сама система. Например, в F.E.A.R., когда ИИ осознает, что он последний оставшийся в живых член отряда, он может выкрикнуть вариацию фразы «Мне нужно подкрепление!». Мы, на самом деле, не вводили механизм прибытия подкреплений к противнику, но поскольку игрок продвигается дальше по уровню, он всё равно встречает больше врагов. Таким образом, игрок может предположить, что следующая группа противников стала следствием озвученного вызова подкрепления, хотя в реальности это не так.
Но чаще, когда это возможно, мы старались выстраивать диалоги между двумя и более персонажами, нежели организовывать единичные выкрики. Например, вместо того чтобы заставить подстреленного ИИ скулить от боли, мы выстроили цепочку так, что кто-то еще запрашивает его состояние, и раненный ИИ что-то говорит в ответ. Когда ИИ ищут игрока, вместо единичного выкрика «Куда он делся?», мы имеем разговор двух ИИ, один из которых спрашивает, видит ли что-либо второй. Второй же может ответить отрицательно, а может и назвать точную, или же подозреваемую позицию.
Кроме этого, диалогами мы иногда объясняем недостаток действий. Если у ИИ просто не получается передислоцироваться, создаётся ощущение что он глуп – но этого ощущения не случится, если добавить диалог, поясняющий, что ИИ знает, что ему нужно переместиться, но он не может сделать этого из-за отсутствия более выгодной тактической позиции. «Мне некуда идти!», скажет он.
Геймеры, идущие на форумы и делящиеся впечатлениями от увиденного, говорят, что их действительно удивило то, что ИИ, судя по всему, действительно понимает, что ему говорят товарищи. «Они не только раздают друг другу приказы, но и ИСПОЛНЯЮТ их!». Но в реальности же, это всего лишь пыль в глаза, и ИИ не координируется между собой, а просто делает то, что ему изначально было предписано отрядным поведением.
Планирование Вне F.E.A.R.
Когда F.E.A.R. ушел в релиз, тот факт, что ИИ приняли хорошо, действительно окупил все старания. Многие люди говорили, что ИИ солдат напомнил им морпехов из Half-Life 1. Half-Life ушел в релиз в 1998-м, а F.E.A.R. – в 2005-м. Значит, похоже, не так уж и много прогресса мы совершили за эти семь лет; и что хуже всего – многим это нравится! А ведь так много ещё можно сделать с игровым ИИ. В отделе Cognitive Machines медиа-лаборатории М.Т.И., мы ведём исследования над другими вариантами техник планирования, которые могут повлиять на будущие поколения игры. Отдел Cognitive Machines использует роботов и компьютерные игры как платформы для исследования понимания языка на человеческом уровне – нашей целью является создать таких роботов и ИИ, которые смогут общаться используя язык, точно так же, как и люди.
Диалоговая система в боях в F.E.A.R. была полностью отделена от системы планирования действий. Мы вручную присоединяли каждую диалоговую строчку к соответствующему месту при помощи кода. И добиться от ИИ того, чтобы нужная фраза была сказана в нужный момент, потребовало от нас множества проб и ошибок. Например, когда солдата полностью разворотило взрывом, у его союзников нет смысла говорить «Доложите статус». С его статусом всё понятно. Но подобные ситуации не всегда очевидны, когда вы пишете С++ код и продумываете, куда стоит добавить диалоговую строчку. Если мы хотим внедрять больше диалогов в происходящее, нам нужно сделать так, чтобы система принимающая решение, понимала что говорит ИИ и использовала эти знания для продумывания плана в дальнейшем.
Мы пытаемся понять, насколько бесшовной может стать интеграция диалоговой системы в систему планирования действий. Если диалоговые строчки мы берём в расчет как что-то, имеющее то же назначение, что и план, то тогда нам нужно иметь возможность формализовать эти строчки точно так же, как мы формализуем действия. Для всего, что ИИ будет говорить, должны быть предпосылки тому, почему ИИ это говорит, и последствия сказанного для мира. Например, если граната упадёт рядом с ИИ, и союзник крикнет ему: «Осторожней! Граната!», то должно быть последствие — этот ИИ должен отбежать от гранаты.
Сложности возникают, когда ИИ может достичь одного и того же последствия, как сказав что-то, так и сделав. Например, солдат может открыть дверь самостоятельно, а может приказать сделать это члену своего отряда. Решение, говорить или сделать самому, должно приниматься согласно расчету стоимости, который требует учёта факторов как ситуации – кто ближе к двери, – так и социальных факторов: кто в отряде выше по рангу? Рядовой ведь обычно не приказывает сержанту.
Ещё один аспект планирования – это распознавание плана. F.E.A.R. сфокусирован на взаимодействии ИИ друг с другом, и если мы хотим сделать игры с большим погружением (immersive), то нужно сделать так, чтобы ИИ взаимодействовал и с игроком; а это гораздо более глубокая и сложная задача, нежели заставить их кружиться вокруг игрока, да стрелять в него.
Проблема в том, что действия игрока непредсказуемы, а следовательно, не всегда понятно, что ИИ должен делать, чтобы быть полезным игроку. Если ИИ сможет распознать тот план, которому, скорее всего будет следовать игрок, он сможет решить, как ему втиснутся в этот план, чтобы стать наиболее полезным игроку [Горняк и Рой 2005].
Например, если в РПГ игрок попытается открыть закрытую дверь, он может последовать плану, согласно которому ему стоит пойти в кузню, и там заплатить кому-то золота, чтобы тот поддерживал огонь, пока игрок сам куёт ключ. Иерархически, подобный план также может быть отображен в контексте грамматически свободного изложения. Затем же, мы, используя методы синтаксического анализа — первоначально созданного для обработки языка — можем предсказать наиболее предпочтительный путь, и, соответственно, дальнейшие действия игрока.
Если мы видим, как игрок собирает золотые монеты, значит, скорее всего, он пойдёт в кузню. Если мы уже видим, как игрок достал золото и идёт в кузню, значит еще более вероятно то, что он идёт туда ковать ключ. Создание ключа требует второго помощника, дабы тот поддерживал огонь в печи! Вот так мы и нашли место, в котором, скорее всего, игрок может принять помощь от ИИ.
Мы применили такое распознавание плана к простому сценарию для прототипа РПГ-игры, где всего три возможных решения прохода через закрытую дверь, и это распознавание действительно помогает ИИ понимать неоднозначную речь игрока, в духе, к примеру «Поможешь мне с этим?». ИИ использует распознавание плана для того, чтобы приложить максимальные усилия и угадать, что же подразумевается под неявной речью.
Заключение.
Планирование в реальном времени наделяет ИИ способностью мыслить. Представьте себе разницу между предопределённым переходом из состояния в состояние и планированием в реальном времени, как разницу между превизуализированной компьютерной графикой в кино, и графикой в играх, визуализируемой в реальном времени. Если мы визуализируем всё в реальном времени, мы можем симулировать влияние света и перспективы, и тем самым создавая результат, более приближенный к реальности. То же самое применимо и к планированию – планируя в реальном времени, мы можем симулировать влияние различных факторов мышления, адаптируя поведение под полученные знания. Через F.E.A.R. мы доказали, что планирование в реальном времени – это рабочее решение для текущего поколения игр. А заглядывая в будущее, планирование кажется многообещающим решением для моделирования группового и социального поведения, улучшения восприятия персонажами языковых команд и создания персонажей-помощников.
Оригинал статьи.
============================================================================
Вот и всё.
А выводы, как всегда, остаются за вами. ©

Читай также








Лучшие комментарии
А вообще, в тексте минимум четырежды это сказано — во-первых, ИИ F.E.A.R. не настолько умный каковым его считают. Действительно многое там рождается из-за незапланированных, чуть ли не рандомизированных комбинаций, которые с субъективной позиции игрока воспринимаются фичами. То есть, будь игра не коридорным шутером в замкнутых пространствах, а иммерсив-симом — боты бы вели себя чуть более чем неадекватно.
То же самое касается и текущих игр (если только кардинально новый подход к созданию ИИ еще не появился. Увы, тут я не в теме) — игрок слишком непредсказуемая скотина, чтобы не ограничивая его возможности, научить ботов распознавать его поведение и подстраиваться под него, при этом не порождая сотнитыщ багов. А что касательно всяких коридорных Call of Duty, то… ну это уже прихоть разрабов, видимо. Брать yoba-вау-эффект количеством противников, а не их качеством.
Поведение игрока непредсказуемо, а перегруженный моделями поведения ИИ может вести себя непредсказуемо просто «сломать игру»: действовать не так, как это от него требуется.
Люди, которые сами же это и выбрали. Массам покупающим КоД, FEAR-like'ИИ вообще нахер не сдался.
Почему не даю? Умный ИИ — это субъективщина, в первую очередь воспринимаемая игроком. Разработчик ставит перед собой глобальную задачу с требованиями, и если эта задача соблюдается, то всё, для него это успех. В F.E.A.R. стояла задача сделать крутые бои, но там условия были в следующем: «закрытые пространства, по 5-8 противников на стычку». И даже в этих условиях авторы добились своей задачи, но уже выведя поведение ИИ на уровень «неуправляемости». Измени условия в сторону более открытых локаций, большего количества противников на стычку, более комплексного взаимодействия или чего-либо еще — и всё, эту итак шаткую в плане контроля систему придётся дописывать охренительным количеством кода и просчитывания новых вариантов, за которыми ЧЕЛОВЕКУ(создателю) следить уже тупо физически проблематично. Написано ж было, что разрабы хвалёного в этом плане Halo 2 сталкивались с тем же.
За Call of Duty, кстати, только что вспомнил, что можно также сказать спасибо консолегеймингу — говорю как человек, поигравший в F.E.A.R. на консоли, что без вспомогательных для игрока фич, по типу замедления времени, такие противники превратили бы игру в садомазохизм.
P.S. Лойс блогу, в карму, максимальный репост гарантирую :{
Вся статья — это по сути рассказ о работе и преимуществах данной системы, но там не говорится, почему в современных «блокбастерах» её не используют.
Может добавишь собственное поясняющее заключение для таких как я? :3
А индюшатники да, еще как экспериментируют с этим до сих пор.
— Выверенная стилистика
— Грамотное применение бампа и эффектов преломления
— Игра неплохих в своей реализации теней
Обсчет большого количества показателей (считай, перемалывание массива данных, постоянно меняющегося). Я помню как банальный pathfinding и анализ действий у AI из игры C&C Generals оземь валил мой древний Celeron 950 в 2003 году с его маленькими кэшем и производительностью. Пускаешь вперед танки штук 50 и видишь в какой момент проц просаживает фпс с целью посчитать, как должны двигаться объекты по карте, и в определенный момент, если ставишь сложность «Brutal» — можно отметить про себя протормаживание из-за ИИ, который воюет с другим ИИ. При этом сцены боя ты не видишь — она не обсчитывается визуально в реальном времени, но обсчитывается поведение объектов.
Ну вот в статье описано, что это итак есть в том же Фире, но, как я понял, актуально для отдельного ИИ как для одной единицы. У каждого врага только своя память. Если солдат столкнулся с тем, что игрок блокирует дверь, и учится обходить её через окно — будет странно, если другие солдаты, перед которыми дверь игрок не блокировал, будут учитывать это знание и сразу же сигать в оконный пролёт.
И дальше я уже сам начинаю уходить в те дебри, о которых слабо представляю — но вот ты видишь, только что появилась логическая дилемма, над которой нужно сломать мозг, чтобы понять как ее решить. А таких дилемм даже до подхода к коду могут быть десятки и даже сотни.
-navmesh можно назвать навигационной сеткой, а потом для дальнейшего использовагтя в тексте — просто сеткой. навмеш как перевод — не очень хорошо звучит
-в статье явно были ссылки на работы других людей, они ещё указаны в квадратынх скобках. линков нет, но почему-то переведены их фамилии. за неимением прямых линков фамилии и названия статей переводить не надо, лучше сотавить оригиналы
-переводить код тоже не очень хорошая затея. это техническая информация, которую лучше сотавлять as is. такие конструкции как ОружиеЗаряжено [bool] или СОСТОЯНИЕ_МИРА m_Предпосылки режут глаз. те, кто шарят программирование, поймут и без перевода, те, кто не шарит, запутается ещё больше
если есть время и желание — можешь попробовать ещё осилить статью ИИ из Killzone 2. кроме того, что там тоже довольно сообразительные боты (хотя из-за темпа игры и сжатости локаций это не слишком заметно), которые научены искать правильные маршруты, в статье наглядно показано, как вообще работет pathfinding на карте с укрытиями:
www.cgf-ai.com/docs/straatman_remco_killzone_ai.pdf