
Это статья — академический рассказ об искусственном интеллекте, генетическом алгоритме, данных, тезисе, точности и предсказании.
Описал её создатель этой игры, идущий к магистерской степени в области машинного обучения в Хельсинском университете, для своей диссертации. Имя не известно.
Хорошо подойдет тем, кто создает игры или просто интересуется выше сказанным. Приступим.

______________________________________________________________________________
1. Выбор системы машинного обучения
Моим языком программирования является C#, я начал изучение платформ машинного обучения, доступных для .NET. Рассмотрел несколько вариантов, таких как Numl, Encog, Sharpkit, но тот, который выделился для меня как наиболее универсальный и всеобъемлющий, был основой Accord.Net.
Я взял скелет предыдущего проекта, чтобы создать прототип, который будет генерировать данные, приближающие то, что я ожидал от своей игры. В частности, прототип случайным образом помещает от одной до десяти защитных структур на экран, затем генерирует от пяти до двадцати врагов, которые движутся с левой стороны экрана, а затем пытаются добраться до правой стороны, в то время как башни стреляют в них.
2. Определить все входные данные
Входные данные для модели очень важны, потому что нужно захватить все, что будет влиять на выход, но исключить то, что не связано и только добавит «шум» к результатам. Для моего прототипа я записал максимальное здоровье, скорость, местоположение и форму передвижения ( ходьба/прыжок/полет) каждого врага, а затем комбинировал это с диапазоном, уроном, скоростью стрельбы, местоположением и площадью эффекта каждой из структур. Если враг/башня не использовались, я заменял значения нулями. *Примечание. В зависимости от используемой модели вам может потребоваться нормализовать ваши данные; то есть обрабатывать его так, что бы все значения находились в диапазоне от нуля до единицы путем деления фактического значения на максимальное возможное значение.
3. Определить свои выходные данные
Выходные данные вашей модели — это информация, которой вы пытаетесь
обучить модели — предсказать. Для моей игры, что я пытался предсказать, было то, насколько эффективной будет группа противников, учитывая оборону и препятствия, с которыми они сталкиваются. В конце волны я записывал расстояние, достигнутое каждым врагом, и отмечал, какому из них удалось достичь другой стороны экрана, эти значения будут считаться результатом, полученные в результате ввода волны. Я сохранил данные ввода и вывода в CSV (Текстовый формат, предназначенный для представления табличных данных), которые являлись образцовыми данными для моей модели.
4. С генерировать достаточное количество данных образца.
Я давал возможность провести пробный запуск без остановок на пару дней, чтобы создать множество данных о выборке. Затем я написал класс для чтения в CSV-data, а затем использовал его в виде набора различных моделей Accord.Net, включая идентичные модели с различными параметрами инициализации, что бы увидеть, какая модель имела самые точные прогнозы и на каком уровне данных их прогнозы стали надежными. Этот процесс уточнения модели занял несколько дней из-за различных методов обучения (контролируемых без надзора), возможных параметров модели и гиперпараметров. Я тестировал одну модель с различными параметрами, выбирал разумно лучшую комбинацию для этой модели, судя по требуемому времени для ее обучения и полученной точности, а затем переходил к следующей модели.
5. Выбор модели
В конце моего тестирования модель с наиболее многообещающими результатами для моего конкретного сценария была глубокой сетью убеждений, формой нейронной сети, которая выделялась при обнаружении признаков. Используя комбинацию контролируемого и неконтролируемого обучения, я обнаружил, что прогнозы стали надежными после примерно ста проб данных с точностью до 90% и они продолжали улучшаться с увеличением доступа к данным до такой степени, что она достигла средней квадратичной ошибки 0,045 после 1.500 образцов или с точностью 95,5%. В дополнение к высокой точности, время обучения было приемлемым, с верхним диапазоном в тридцать секунд.
6. Внедрение своей модели
На этом этапе у вас уже должен быть образец рабочего кода для вашей модели выбора, поэтому его реализация в вашей реальной игре должна быть такой же тривиальной, как изменение фиктивных данных на реальные данные и применение прогнозов, которые он делает для вашей логики игры. Ключевое, что вам нужно сделать, — это уменьшить время, которое потребуется, когда вы тренируете свою модель, поскольку она обычно занимает более продолжительное время по мере увеличения объема данных. Что я сделал, когда нужно вводить новые данные, я скопировал существующую модель, а затем назначил поток с низким приоритетом для обучения копии. Когда обучение закончилось, я заменил существующую модель обновленной копией. Закрыл доступ к живой модели с помощью мьютекса (аналог одноместного семафора, служащий в программировании для синхронизации одновременно выполняющихся потоков), чтобы предотвратить проблемы параллелизма.
7. Сделать свою игру
Итак, теперь вы выбрали модель машинного обучения, данные, которые она должна идентифицировать, и знаете, как вы собираетесь использовать выходные данные, что бы продолжить игру. Возможно, вы решили использовать более чем одну модель для разных аспектов игрового процесса или использовать другие аспекты выбранной вами структуры, поскольку вы будете внедрять фреймворк в свой проект, что бы в любом случае реализовать выбранную модель. Существует множество приложений машинного обучения, таких как динамическое изменение событий игры для поддержания напряженности, использование генетических алгоритмов в качестве основы для создания игрового контента или анализа игровых моделей, чтобы максимизировать постоянную вовлеченность игрока.
8. Решить, статическая или динамическая модель?
После того, как вы закончите свою игру, вы можете использовать ее для создания достаточных данных для обучения модели, экспорта её на текущем уровне производительности, а затем отправить экспортированную модель с игрой для использования без дальнейшей подготовки. Это позволит отказаться от вычислительных требований, необходимых для непрерывного обучения, что является важным соображением для мобильной игры. Однако это может повлиять на уровень сложности игры, если игроки поймут «слепые места» и уязвимости игры. Вместо этого вы можете решить частично обучить модель, насколько сможете, а затем позволить этой модели постоянно обновляться с помощью живых данных, генерируемых игроком.
Этот последний гибридный подход отражает лучшее из обоих миров, потому что вы начинаете с достаточно хорошей модели, которая будет продолжать улучшаться на основе собственных действий игроков. Для моей собственной игры я решил отправить модель с нулевыми данными и позволить ей учиться, когда учится и игрок, поэтому ошибки и промахи будут частью повествования. В других играх это может быть опасное решение, смотря, что отвечает за модель в конкретном варианте, но в моем случае это просто решение о том, каких врагов послать на локацию. Так что в худшем случае модель просто отправит врагов, которые недостаточно хорошо оснащены для борьбы с защитой(башнями), с которыми они сталкиваются.
9. Рассмотреть другие приложения
Во время тестирования моделей я тщательно изучил структуру Accord.Net и решил сделать врагов более динамичными, чем они были в моем прототипе, используя доступную реализацию генетических алгоритмов. Я знал, что это не окажет большого влияния на настоящий игровой процесс, но я подумал, что было бы полезно обеспечить каждому врагу уникальные атрибуты, чтобы сделать с генерированные данные немного более «живыми» и, надеюсь, улучшить производительность противника в течение игры в сочетание с производительностью модели.
При создании нового файла сохранения я генерирую случайный пул генетики для каждого типа врагов, состоящий из восьми хромосом, которые изменяют максимальную скорость здоровья, скорость ходьбы и другое, так что увеличение одного уменьшает другое. Затем модель машинного обучения сравнивает предсказание базового врага с противником, с использованием определенной генетики для определения относительной пригодности этой генетики, и такая генетика с наивысшем уровнем пригодности, скорее всего, будет передаваться следующему поколению.
______________________________________________________________________________
Игра была создана, в первую очередь, для диссертации, где цель увидеть, насколько хороша созданная модель ученого, а именно сеть глубоких убеждений, как она работает против игроков и с нулевым предварительным обучением. А это значит, что когда вы впервые начинаете играть в игру, она так же ничего не знает и учится играть так же, как и вы. Когда вы будете играть, входные и выходные данные отправляются анонимно в Keen.io для анализа к диссертации человека, поэтому чем больше людей поиграют, тем увереннее будут утверждения и результаты.
Его друг разработал врагов, башни, атрибуты и ландшафтные объекты. Он взял его проекты и анимировал их с помощью Spriter Pro, написал сценарий ветвящегося диалога, используя Articy: Draft, а затем объединил все полученные результаты с использованием механизма FlatRedBall и среды MonoGame.
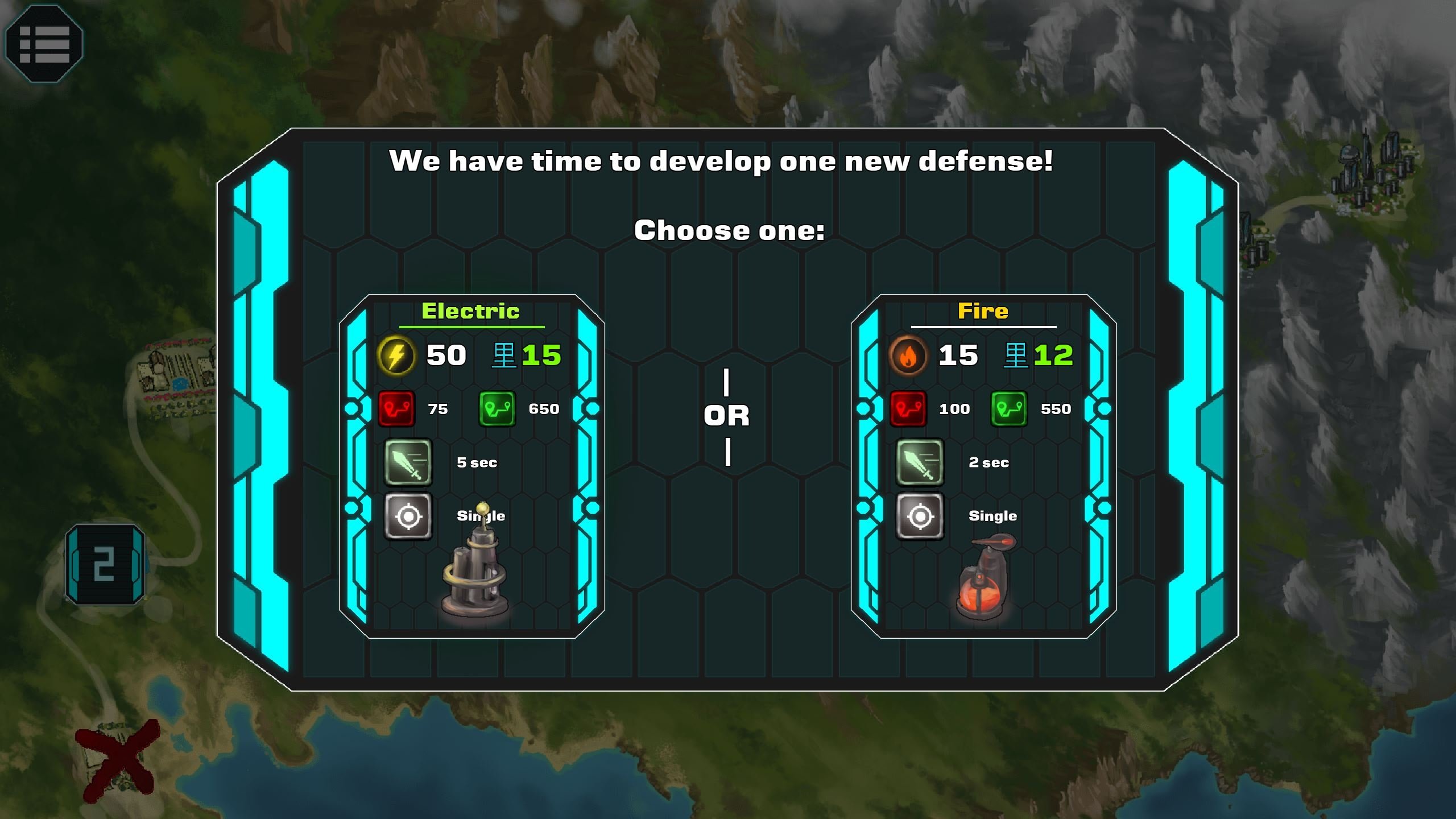
В совокупности есть 15 вражеских типов, шесть типов башен, десять карт и около 2.500 фрагментов диалога, четыре концовки игры, и для завершения одного прогона требуется около часа времени.
ссылка на игру:
cabrill.itch.io/ai
Счастливо.








Лучшие комментарии
Сам пост является переводом или может пересказом текста диссертации?
Если на глаза попадутся еще материалы, на схожую тематику, а может появится данная диссертация, отправлю вам ссылки в личные сообщения, почитаете.