
Всем привет! 11 мая 1997 года произошло уникальное событие, когда компьютер Deep Blue, разработанный компанией IBM выиграл матч из 6 партий у чемпиона мира по шахматам Гарри Каспарова. С той поры многие компании стали вкладываться в развитие искусственного интеллекта, который сможет продемонстрировать свое мастерство в подобных ситуациях. В этом материале я расскажу о шести проектах, где компьютер снова одержал верх над человеком.
Libratus и Техасский холдем
В 2017 году ученые из университета Карнеги-Меллон в Питтсбурге решили создать искусственный интеллект, который сможет обыграть профессиональных игроков в Техасский холдем. От анализа эмоций и жестов сразу же отказались, так как пока нет технологий способных реализовать столь сложные алгоритмы. Поэтому решили просчитывать различные комбинации и ставки.
Каждый ход отдельно анализировался, после чего искусственный интеллект рассматривал возможные последствия. Если соперник предпринимал неожиданный манёвр, то программа добавляла его в свою базу данных и в последующих играх могла сама его применить в одной из ситуаций.
Данный искусственный интеллект назвали Libratus, а чтобы сформировать стратегии для всевозможных ситуаций, разработчики Libratus использовали суперкомпьютер Bridges стоимостью почти 10 миллионов долларов. Bridges играл против самого себя день за днем, создавая определенные выигрышные последовательности методом проб и ошибок.



Когда программа была полностью готова, то в качестве показательного матча пригласили сыграть четверых ведущих игроков: Джейсона Леса, Донга Кима, Дэниэла Макоули и Джимми Чоу.Турнир длился с 11 по 31 января 2017 года, призовой фонд составил 200000 долларов, из которых 10% гарантированно доставались каждому игроку. Во время турнира Libratus днем соревновался с игроками, а ночью совершенствовал свою стратегию, анализируя прошедшие результаты. Таким образом, он мог постоянно исправлять обнаруженные недостатки.
К концу чемпионата искусственный интеллект обыграл людей, заработав фишек на сумму 1800000 долларов, но из-за правил сам Libratus не получил призовых денег. После турнира Донг Ким сказал в одном из интервью, что чем дольше шла игра, тем сильнее создавалось ощущение, что Libratus может видеть его карты.
BotPrize и Unreal Tournament 2004
Следующий турнир, где искусственный интеллект победил человека, называется BotPrize, но он довольно необычный. В качестве тестовой площадки использовался шутер от первого лица Unreal Tournament 2004. Разработчики, принявшие участие в турнире, должны предоставлять созданных ботов, которые будут пытаться выдавать себя за людей. Побеждает тот бот, которого определенное количество раз примут за человека.
Соревнование спонсировалось компанией 2К Games и называлось BotPrize. Официально было зарегистрировано в 2008 году и представляло собой адаптацию теста Тьюринга. Во время него люди и боты анонимно вступают в режим deathmatch, цель которого — убить как можно больше противников в течение заданного промежутка времени.
Unreal Tournament 2004 была выбрана не просто так. Разработчикам необходимо было учитывать не только перемещение в трехмерном пространстве, но и частые схватки сразу с несколькими противниками. Судьями выступали живые игроки, которые наблюдали и помечали анонимов как людей или ботов. Если более 30% судей назовут бота живым, то он побеждает в соревновании. Все разработчики были в равных условиях. Перед соревнованием они должны были использовать программы GameBots 2004 и Pogamut 3, причем в последней содержались уже готовые образцы ботов.
И вот в 2012 году сразу две команды победили в турнире. Бот UT^2 был оценён, как живой человек достигнув 51,9% голосов. Над его созданием трудились выходцы из Техасского университета, а именно: профессор Ристо Мииккулайнен с докторантами Якобом Шрумом и Игорем Карповым.
Другой бот от румынского программиста Михайя Польчану назывался MirrorBot. В отличие от своего оппонента, он был чуть «живее» и получил 52,2% голосов. Интересно то, что реальные игроки показали результат 41,4%.
Обе команды рассказывали, что им приходилось ограничивать своих ботов, чтобы они не становились грозными машинами для уничтожения всех соперников. UT^2 снизили точность попаданий за счет повышения скорости движений и стрельбы с длинных дистанций.
А вот MirrorBot мог имитировать действия другого игрока в реальном времени. Делал он это с небольшой задержкой и без полной точности, так что со стороны они казались другими. Он мог на некоторое время запоминать свою цель, следовать за ней и уклоняться, в зависимости от направления стрельбы противника. Также бот забывал про свою первичную цель, если другой противник атаковал гораздо агрессивнее.
IBM Watson и Jeopardy!
После победы Deep Blue над Каспаровым IBM искала новый вызов. Компьютеры не умеют быстро давать чёткие ответы и предоставляют тысячи результатов поиска, соответствующих ключевым словам. И тогда сотрудники IBM со временем пришли к идее, что необходимо создать такую машину, которая сможет отвечать на вопросы викторины Jeopardy!, которая в России адаптирована под программу «Своя игра».
Суть в том, что в Jeopardy! программа должна сначала расшифровывать естественный человеческий язык в вопросе, выяснить, о чем спрашивают, а затем дать правильный ответ. Причем чем короче вопрос, тем труднее находится правильное решение. Также трудности могут возникнуть, если, наоборот, программа должна задать вопрос на полученное утверждение.
К 2006 году разработчики сформировали компьютер под названием Watson, но он был очень медленным и давал примерно 10% правильных ответов. На исправление ошибок команде предоставили 5 лет. К 2010 году он уже мог конкурировать с живыми игроками, а на 2011 год решили назначить показательное шоу с известными победителями прошлых матчей.

Причем между IBM и Jeopardy! часто возникали конфликтные ситуации. Например, руководство шоу считало, что Watson будет использовать кнопку для ответов гораздо быстрее обычного человека. Даже предлагали сделать аватар с механической рукой, чтобы хоть как-то замедлить процесс.
Но никаких изменений не сделали, хотя даже менеджер по проекту Watson говорил, что кнопка для ответа будет активирована сразу же после зачитывания последнего слога вопроса. Но при этом, если Watson не знает, как ответить, то панель останется нетронутой.
Собственно, а как происходит процесс обработки внутри машины? Сначала более 100 алгоритмов анализируют вопрос и находят множество правдоподобных ответов. Еще один набор алгоритмов сортирует их и выставляет соотношения, доказывающие или опровергающие полученный результат. В конечном счете будет выдан ответ с наилучшей оценкой.

Во время игры Watson был отключён от интернета, но имел доступ к 200 миллионам страниц, загруженных на четыре терабайта дискового пространства. Хотя Watson часто отвечал правильно, но он был не идеален. Некоторые вопросы его или сбивали с толку, или он просто не мог найти подходящий ответ.
Под конец шоу Watson вышел на первое место с одним миллионом долларов, которые были отданы в благотворительные фонды. IBM показала, что их машина может быстро распознать вопрос на английском языке и с высокой точностью дает необходимый ответ. Данный успех позволил в 2013 году испытывать Watson в медицинских учреждениях для повышения качества работы персонала, но это уже совсем другая история.
AlphaGo и Го
Го — одна из древнейших настольных игр. Считалось, что компьютер не способен играть на равных с профессиональным игроком из-за невозможности перебора всех доступных вариантов развития. Компания DeepMind решила бросить вызов этому утверждению и стала разрабатывать программу AlphaGo.
Разработчикам пришлось делать алгоритм, имитирующий интуицию человека, чтобы избежать обычных пересчитываний комбинаций. Программе показали 100 тысяч игр, загруженных из интернета. Сначала её заставляли имитировать действия человека, а затем она множество раз играла против себя.
В результате получилось так, что AlphaGo стала оценивать позиции камней на доске и рассчитывать процент победы. Когда программа выбирала самый оптимальный вариант, она рассматривала дальнейшие возможные комбинации в ответ на её ход. Таким образом, AlphaGo думала на десяток ходов вперед.
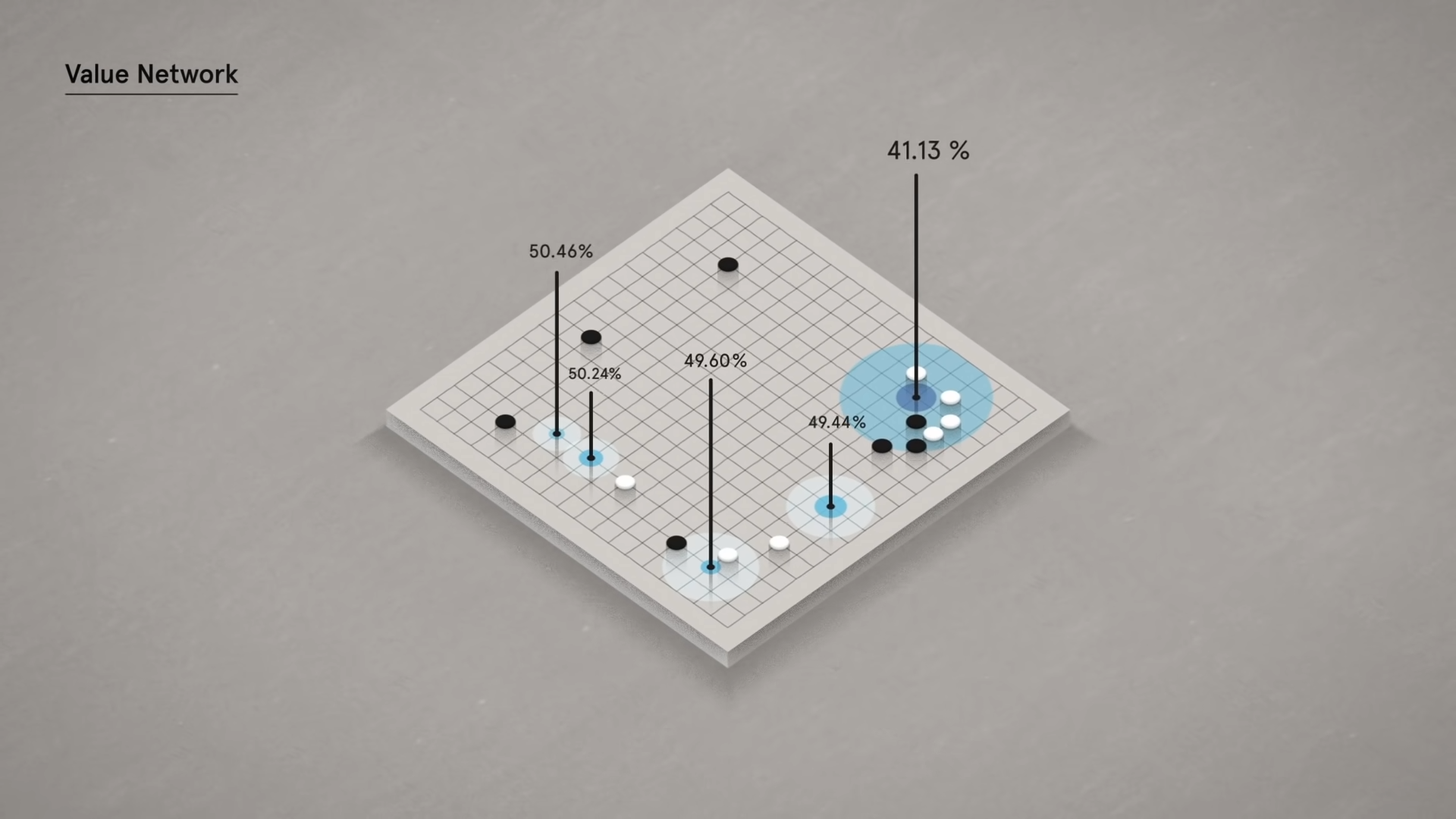
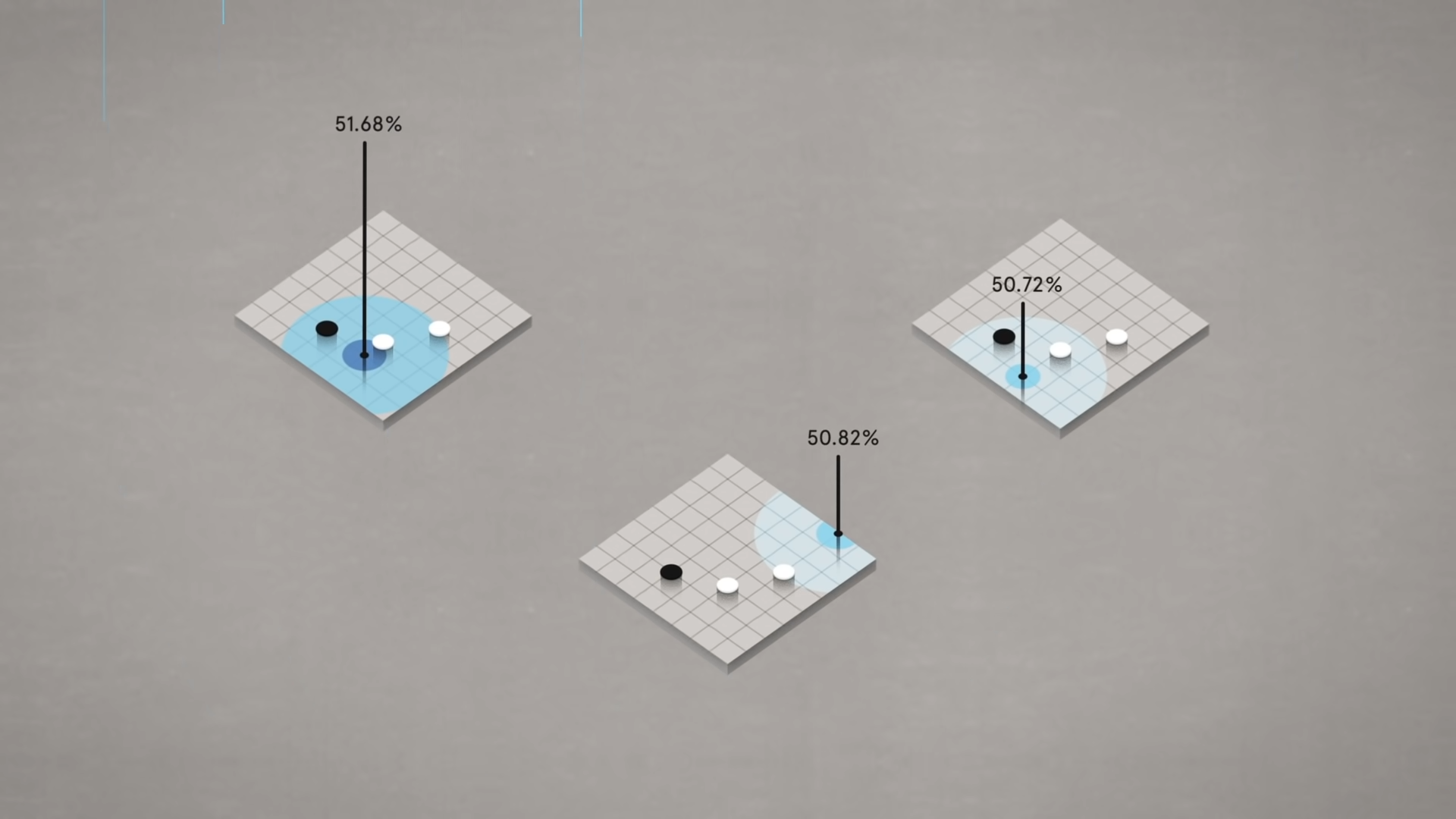
Интересно то, что программа не пыталась заработать как можно большее число очков, а реагировала на вероятность своей победы. AlphaGo могла беспрепятственно пожертвовать несколькими очками, если в дальнейшем она всё равно сможет обыграть соперника. Поэтому в некоторых матчах она могла выигрывать с разницей 0,5-2,5 очков.
Когда в 2015 году AlphaGo обыграла чемпиона Европы Фань Хуэйя, то сообщество го двояко восприняло эту новость. Многие говорили, что Фань Хуэй слишком слаб и данные победы не показатель превосходства искусственного интеллекта в игре против человека. Ли Седоль, один из сильнейших игроков в истории го, прокомментировал, что AlphaGo достигла высшего любительского уровня в этом матче, но еще не профессионального.
DeepMind решила не прощаться с Фань Хуэйем и предложила ему помочь найти дефекты в AlphaGo. Он согласился и помог им исправить ряд ошибок перед матчем с Ли Седолем, который был уверен, что выиграет со счетом 5:0 или 4:1.

Соревнования прошли в марте 2016 года, и все пять матчей транслировались на корейском, китайском, японском и английском языках. Суммарно за игрой наблюдало больше 60 миллионов человек из разных стран.
Первые три матча Ли Седоль проиграл. После второй партии он сказал, что если от первого поражения он был удивлен, то после второго у него нет никаких слов. В четвертой игре ему удалось обыграть AlphaGo, выполнив уникальный ход, который даже другие профессиональные игроки не сделали бы в тот момент.
AlphaGo тоже не ожидала этот маневр и оценила его появление с вероятностью в 0,007%. После этого она стала заново просчитывать ходы и совершила ряд ошибок.
К сожалению, Ли Седоль проиграл и заключительный пятый матч. По его словам, он открыл для себя новые моменты, а его победа в четвертой игре доставила ему такие положительные эмоции, что он ни на что бы их не променял.

В 2017 году прошли ещё матчи против живого игрока. На этот раз пригласили китайского профессионального игрока Кэ Цзе, который занимал первое место в рейтинге по своей стране. После поражения Ли Седоля многие игроки хотели сыграть с AlphaGo, но выбрали именно Кэ Цзе, который ещё на играх 2016 года утверждал, что может победить программу.
Первые три тренировочных матча прошли зимой в онлайн формате, и Кэ Цзе проиграл во всех. Однако он всё равно был уверен, что одержит победу на официальной встрече в мае. Но чуда не случилось, и последующие игры он тоже проиграл, хотя первая из них завершилась с разницей в 0,5 очка.
Перед финальной игрой AlphaGo сыграла ещё показательные матчи. Сначала в паре с живым игроком против прошлой версии и другого живого игрока, а затем сразу против пятерых. Результат был везде один. Новая версия AlphaGo выиграла все матчи у своих оппонентов.


На протяжении всех игр программа показала способность к креативным решениям, что удивило многих игроков. Некоторые ходы противоречили классической теории го, но они доказали свою эффективность, а некоторые профессионалы даже стали использовать их в своих играх.
Увы, но новые матчи с живыми игроками больше не устраивали. Часть команды перешла на новые проекты, а разработанные алгоритмы AlphaGo решили использовать в медицине. Это привело к тому, что DeepMind заключила соглашение с Национальной службой здравоохранения Великобритании для применения искусственного интеллекта в анализе медицинских данных.
AlphaStar и StarCraft 2
После развития программ для пошаговых игр компания DeepMind решила, что в качестве нового проекта стоит создать искусственный интеллект, который будет обыгрывать профессионалов в компьютерной игре StarCraft 2. Её отличие в том, что она не пошаговая, а действия проходят в режиме реального времени, то есть игроки одновременно принимают решения.
Для обучения такого искусственного интеллекта команда DeepMind запросила у Blizzard анонимные игровые данные людей, участвующих в соревнованиях по StarCraft 2. После этого разработчики загрузили полученные материалы в свою новую программу под названием AlphaStar.
На их основе искусственный интеллект смог имитировать основные микро- и макростратегии, которые применяются в StarCraft 2. Затем началось дополнительное развитие через симуляции множества боев, на основе которых AlphaStar вырабатывала победные стратегии. Из-за большого объема обработки данных разработчики решили ограничиться лишь одной из трех рас, доступных в игре, а именно были выбраны протоссы.

На первый матч позвали игрока с ником TLO. Он являлся одним из лучших профессиональных игроков за протоссов. К его удивлению, он проиграл со счетом 5:0. TLO заметил, что AlphaStar продемонстрировала стратегии, о которых он раньше и не думал. Через неделю пригласили одного из 10 сильнейших игроков за протоссов с никнеймом MaNa, который тоже проиграл со счетом 5:0.
Матчи прошли по всем профессиональным правилам на специальной турнирной карте и без каких-либо ограничений. Но при этом было замечено, что AlphaStar могла наблюдать за своими и вражескими юнитами без перемещения камеры, то есть программа полноценно использовала уменьшенную карту игры. И как только разработчики ограничили область видимости, как у человека, то искусственный интеллект сразу стал неправильно отрабатывать данные.
К сожалению, пока даже минимальные изменения в правилах могут повлиять на работу AlphaStar. Если будут добавлены новые объекты или юниты, то программе придется начинать обучение сначала, так как она не сможет сразу адаптироваться под новые условия. Поэтому команде DeepMind предстоит ещё долгая работа над столь тяжелым проектом.
Eurisko и Traveler
В истории серии BattleTech я уже рассказывал про настольную игру Traveler. Это научно-фантастическая ролевая игра, впервые опубликованная в 1977 году. В ней можно путешествовать между различными звездными системами и участвовать в таких мероприятиях, как исследования, наземные и космические сражения, межзвездная торговля. По ней часто проводились турниры, где игроки рассчитывали, как построить космический флот, который победит всех врагов, не превышая воображаемый оборонный бюджет в один триллион кредитов.
Казалось бы, что раз часть механик в соревнованиях не используется, то всё будет достаточно просто. Но это совершенно не так. Игроки должны были учитывать различные факторы: какой толщины броня, сколько топлива везти, какие типы оружия, двигателей и компьютерной системы наведения использовать.
Мощный двигатель сделает корабль быстрее, но для этого может потребоваться больше топлива, усиленная броня обеспечивает защиту, но увеличивает вес и снижает маневренность. Поскольку флот может иметь до 100 кораблей, то количество переменных огромно даже для цифрового компьютера.

Однако Дугласа Лената, доцента программы искусственного интеллекта Стэнфордского университета, это ничуть не остановило. Он не был фанатом Traveler и даже никогда не играл в неё сам. Но он всегда хотел создать особый искусственный интеллект, который сможет выполнять различные трудные задачи.
В его распоряжении был научно-исследовательский центр Xerox PARC, где около месяца, по десять часов каждую ночь на сотне компьютеров программа под названием Eurisko обрабатывала различные данные для создания победоносного космического флота.
В качестве исходных данных Ленат загрузил в программу обширный свод правил. Eurisko формировала флотилии и устраивала виртуальные бои от двух до тридцати минут. Каждое утро Ленат приходил и изучал полученные данные.
Сначала всё было плачевно. Большая часть стратегий выглядела непрактично или нелепо. Несколько раз Eurisko предложила изменить правила, чтобы одержать победу над соперником. Но Ленат был стойким, он корректировал данные, а затем запускал эмуляцию по новой

В результате долгих анализов Eurisko выдала самый подходящий результат, который удивил на турнире абсолютно каждого. Программа посчитала, что рой дешевых и защищенных кораблей выстоит и одержит победу над дорогостоящим флотом, состоящим из маневренных тяжеловооруженных судов.
В предоставленном построении было девяносто шесть кораблей, большинство из которых медленные из-за их тяжелой брони. Огневая мощь ориентировалась не на паре больших дорогих орудий, а на десятке дешевых пушек.
Помимо этого, было ещё два козыря. Если бы флот Лената всё же был на грани уничтожения, то на помощь приходила маневренная спасательная капсула, которая могла уклоняться от всех выстрелов на протяжении последующих ходов, пока флотилия противника не лишится топлива и боеприпасов.
Если же данная тактика применялась бы против Лената, то в его флоте находился корабль, оснащенный сложной системой наведения и гигантским ускорителем. Его единственной целью было уничтожение вражеских спасательных шлюпок.

Ленат одобрил выбор Eurisko и отправился на турнир. Поначалу все смеялись над его флотом и считали, что он проиграет в первом же раунде. Однако после череды побед игроки стали жаловаться, что Ленат мухлюет, и его надо дисквалифицировать. Судьи были недовольны, но основные правила не были нарушены, поэтому Ленату разрешили играть дальше, после чего он стал победителем турнира.
На следующий год Ленат решил закрепить свой успех и показать, что его победа не была случайностью. Ситуация стала гораздо сложнее. Судьи решили за несколько дней до турнира подкорректировать правила. Отныне флот не сможет победить, если он не будет чрезвычайно мобильным.
Ленат успел загрузить новые правила, и Eurisko ещё больше поразила участников турнира. Искусственный интеллект выдал новую стратегию, по которой критически поврежденные судна должны самоуничтожаться или по ним будет вестись огонь из соседних дружественных кораблей. Тем самым общий параметр мобильности значительно повышался и флот мог без проблем доминировать над противником.

Без всяких проблем Ленат снова победил в новом чемпионате. Конечно, судьи турнира остались недовольны методами Лената. По их мнению, его стратегия слишком жестока и аморальна. Если бы это происходило в реальных условиях, то ни один из военачальников не пожертвовал бы тысячами своих солдат. Также судьи угрожали закрыть следующий турнир, если Ленат снова в нем примет участие.
Дуглас решил не становиться ещё большим врагом у сообщества Traveler и согласился с условием, что он больше не будет участвовать в соревнованиях. Изначальная цель удалась, и общество увидело, что искусственный интеллект способен проанализировать многочисленные вариации в такой сложной игре, а значит данные наработки можно использовать и при решении реальных проблем.
Итог
Искусственному интеллекту предстоит ещё очень долгий путь до того момента, когда он станет самостоятельно разрешать различные проблемы. Рассмотренные примеры показали, что даже несмотря на победу над человеком, программы обладают существенными недостатками.
Однако данные проекты дали хороший толчок для развития в этой сфере. Быть может, что в ближайшем десятилетии мы ещё увидим небольшие турниры по каким-нибудь играм с участием нескольких компьютеров с искусственным интеллектом.









Лучшие комментарии
Пфф, ха! Настолько людей недооценивать...
TLO с alphastar играл оффрейс, а не основной расой, и MaNa по-моему одну игру всё-таки выйграл. Потом его обыгрывали все кому не лень.