
Если Вы хоть немного интересуетесь компьютерами, то наверняка заметили, что почти у любого современного процессора количество «логических процессоров» в два раза больше, чем количество ядер. И если с ядрами ещё более-менее понятно – это количество отдельных физических вычислительных единиц, то в чем смысл логических ядер, уже не так очевидно. В процессорах Intel логические ядра – это реализация технологии Hyper-Threading и компания уверяет нас, что одно из преимуществ технологии — «Параллельная работа с несколькими ресурсоёмкими приложениями при сохранении прежнего уровня быстродействия». Но откуда берётся это быстродействие, если ядра не физические, а логические? И зачем же вендоры оставляют нам возможность отключить эту технологию в настройках BIOS? Попробуем разобраться.
Ускорение вычислений
Традиционно, методы улучшения производительности были сконцентрированы на увеличении мощности самих ядер. Есть три основных подхода: увеличение рабочей частоты ядер, неупорядоченное выполнение операций и увеличение размера кэша. Увеличение частоты процессора – самый очевидный вариант: процессор может выполнить больше операций в секунду, а значит и пользователь быстрее получит свой результат. Но на самом деле не всё так просто: процессоры и так работают на очень высоких частотах и нередко просто ждут, когда новые данные для обработки придут из, скажем, оперативной памяти. Чтобы как то сгладить это ожидание, процессор может попытаться предсказать, какими будут эти данные и продолжить вычисления на основе этих предположений, но тогда и цена ошибки предсказания будет велика – придется возвращаться назад.
Есть ещё одна техника — «Параллелизм на уровне команд». Суть её состоит в использовании возможности процессора выполнить одновременно сразу несколько операций. Но обычно программы написаны так, чтобы выполняться последовательно, поэтому нам нельзя просто запустить одновременно несколько инструкций. Необходимо в некотором «окне» инструкций определить независимые и отправлять их на выполнение одной пачкой.
Однако один из главных факторов, замедляющих работу процессора – доступ к памяти. Мы можем выполнять миллионы операций в секунду, но если нужно получить данные от диска, то ждать их придется несколько миллисекунд. Это несоизмеримо долго. Да, мы можем обратиться к оперативной памяти, загрузив в неё данные заранее, но по меркам процессора, такой подход тоже долгий. Чтобы бороться с этой проблемой, был придуман кэш – очень быстрая память, расположенная прямо в процессоре. Туда попадают все данные с которыми работает процессор. После обработки, данные остаются в кэше, пока их не вытеснят новые данные. Но если процессору понадобится что-то, с чем он совсем недавно работал, то он вполне может избежать обращения к оперативной памяти. Кэш-память очень дорогая, и поэтому имеет иерархическую структуру. L1-кэш расположен максимально близко к ядру и имеет самую высокую скорость, но его мало – несколько сотен килобайт. L2 помедленнее, но зато его больше, несколько мегабайт. Обычно сейчас есть и L3-кэш, и его количество исчисляется десятками мегабайт. Для сравнения, сейчас я пишу этот текст на машине, где скорость доступа к L1 около 1 наносекунды, L2 – 3нс, к L3 – 10нс. А к оперативной памяти целых 67нс! Как видно, увеличение размера кэша – очень полезная техника. Но всегда может случиться кэш-промах, ситуация, когда нужных данных в кэше нет, и тогда придется выполнять честное обращение к памяти, поэтому просто увеличивать размер кэша не получится, к тому же, он дорого стоит, занимает львиную долю места на кристалле и выделяет огромное количество тепла.
Как видим, ни одна из этих техник не даёт 100%-ной эффективности, так как возможности параллелизма на уровне инструкций ограничены, увеличение частоты процессора нивелируется долгим доступом к памяти, а увеличение объёма кэша – тяжелое и дорогое занятие.
Впрочем, пока одна задача ждёт выполнения какого либо события, мы вполне можем работать над другой задачей. Поэтому для параллельного запуска независимых частей программ архитекторы операционных систем придумали концепцию потоков. Поток — это некая независимая задача, для выполнения которой периодически выделяется процессорное время. Один или более потоков составляют процесс. Процесс — олицетворение программы: он хранит программные инструкции, информацию о пользователе, запустившем процесс и прочую служебную информацию. Потоки могут иметь общие ресурсы и даже обмениваться информацией, чтобы обеспечивать согласованность действий. Во время работы, процессор просто время от времени переключается между разными потоками и так, почти одновременно, выполняет разные программы или даже разные части одной программы. Эта техника так хорошо работала, что операционные системы сами стали многопоточными. Например, чтобы подготовить видео с YouTube для вывода на экран, браузеру не нужно 100% процессорного времени, поэтому он может периодически уделять внимание проверке, не пришло ли Вам новое письмо на почту в соседней вкладке. Позже, при распространении многоядерных процессоров эта техника лишь лучше раскрывала свой потенциал, так как потоки можно было выполнять на разных ядрах.
Однако, многопоточный подход к написанию программ даёт не только преимущества. Один из негативных факторов Вы уже могли заметить: переключение между потоками. Дело в том, что для этого переключения необходимо сохранить всю информацию, которая будет нужна отключаемому потоку для возобновления работы в дальнейшем. Данная операция требует времени, пусть и небольшого, поэтому, если приложению доступно только одно ядро процессора, однопоточный подход может оказаться быстрее. Но бывают и исключения. Например, когда один поток программы не может продолжить работу, так как ждёт какие то данные, а другой поток готов к работе. В таких случаях плата за переключения между потоками с лихвой компенсируется амортизацией ожидания данных.
Кроме того, потоки необходимо синхронизировать и следить за использованием общих ресурсов. Так, например, при одновременной записи в один и тот же файл из двух разных потоков, мы рискуем получить бесполезное месиво из разных данных от каждого потока. Необходимо устанавливать порядок записи. Схожие проблемы возникают, когда один поток уже ждет данные из другого, «неуспевающего» потока. Такие проблемы сильно увеличивают требования к разработчикам программного обеспечения.
Hyper threading
Технология Hyper-Threading позиционируется, как технология одновременной многопоточности. Напомню, что появилась эта технология во времена, когда многоядерные процессоры ещё не были так распространены и возможность использовать одно физическое ядро, как два логических была весьма эффектной. Два логических ядра использовали общие вычислительные ресурсы, но обладали собственным архитектурным состоянием. Тем самым состоянием, которое нужно было сохранять для переключения потоков. В результате операционная система могла планировать выполнение сразу двух потоков, что сулило увеличение производительности за счёт более полного использования вычислительных ресурсов.
Для лучшего понимания, рассмотрим процессор чуть ближе:
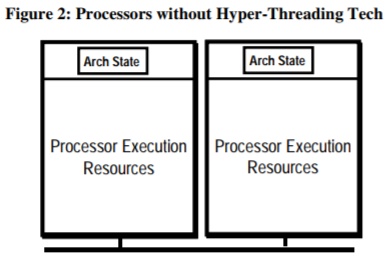
Здесь мы видим честный двухядерный процессор. У каждого ядра есть architecture state – часть, хранящая состояние процессора во время вычислений, в основном, это регистры. Кроме этого, у каждого ядра есть набор вычислительных ресурсов – единиц, занимающихся непосредственно работой.
В число execution resources входит много разных модулей. Например, ALU(arithmetic and logic unit), которые занимаются простыми арифметическими и логическими преобразованиями, FPU(floating-point unit), ответственные за работу с дробными числами, ACU(adress calculation unit), необходимые для работы с адресами памяти. Вычислительных юнитов может быть(и обычно бывает) гораздо больше: например, есть очень специфичные SIMD модули, способные за один такт процессора обрабатывать большие объёмы данных. Но для нас важно то, что эти вычислительные ресурсы разные и их много, например у новых Ryzen Matisse(процессоры AMD 2019 года) 4 ALU. Очевидно, что при выполнении большой однообразной задачи, часть вычислительных ресурсов просто будет простаивать. Так, при работе с графикой нам редко нужны ALU, так как почти все данные дробные.
Чтобы решить обозначенную выше проблему простаивания ресурсов, Intel предложила иную схему процессора:
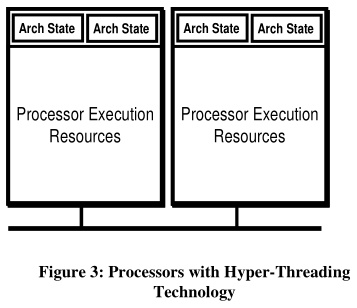
Теперь несколько состояний делят общие ресурсы. В результате, пока один поток видеоигры обсчитывает геометрию кадра, другой поток, используя ресурсы того же ядра, может обрабатывать искусственный интеллект. Но это будет хорошо работать лишь в случае, когда потокам нужны разные ресурсы.
В своём описании Intel приводит очень наглядный пример:
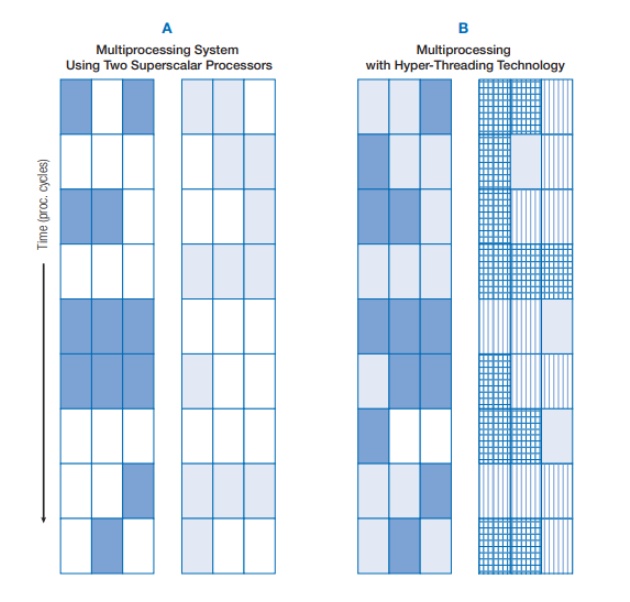
Слева обычный двухъядерный процессор. Его ядра обрабатывают синие и светло-синие потоки. По большому количеству белых клеток видно, что процессор много простаивает.
Справа двухъядерный процессор с Hyper-Threading. Первое ядро обрабатывает синие и светло-синие потоки, а второе – штрихованные синие и светло-синие. Как видим, белые клеточки(простаивание) встречаются редко, нагрузка близка к пиковой, а значит и ресурсы используются более оптимально.
Преимущества и недостатки
Как видим, данный подход к ускорению работы процессора так же не идеален. Резюмируя вышесказанное, можно отметить плюсы и минусы:
+ Большая загрузка вычислительных ресурсов, минимизация их простаивания.
+ Амортизация ожидания событий или данных потоками.
— Ожидание занятых вычислительных ресурсов
— Разделение кэша между большим количеством ядер
— Высокие требования к программистам, так как для получения преимуществ в контексте выполнения одной программы, необходима многопоточная реализация этой самой программы.
Практическое применение
Для проверки преимуществ, которые даёт Hyper-Threading, были проведены тесты скорости сборки ядра linux и прогон бенчмарков LinPack и Prime95. Тесты проводились на процессоре Intel Core i5 5200U(2 ядра, 4 потока).
Начнем со сборки linux. Это версия 5.0.3 с патчами дистрибутива Arch. Использовался компиллятор gcc 9.2.0. При использовании только 2-х реальных ядер время сборки составило 2 часа 24 минуты. Когда же были использованы все 4 потока, время удалось сократить до 1 часа 41 минуты. Но самым интересным сценарием оказывается сборка при включенном Hyper-Theading в 3 потока: 1 час 39 минут. Как видим, сказывается тот факт, что алгоритмы компилляции используют ограниченный набор вычислительных юнитов и на 4 потока этот набор плохо делится: потокам нужно друг друга ждать. А засорение кэша дополнительными потоками уже становится заметным.
Далее, LinPack Xtreme. Стандартный тест(на 3GB), 3 прохода. Он также удивил: при использовании 4-х потоков среднее время теста составило 80,5 секунд. А при использовании 2-х потоков – 83,3 секунды. То есть, в случае линейной алгебры, выбивание кэша дополнительными потоками оказалось не таким фатальным.
Последним выступает бенчмарк Prime95, который основывается на поиске простых чисел. Особенность данного теста состоит в том, что для поиска простых чисел необходим малый набор операций, но выполнить этих операций нужно много. Результаты встроенного бенчмарка для 8192K: на 2 потоках(2 физ. ядрах) — в среднем 34.176ms. на тест, а на 4-х потоках 34.918ms. Это тот случай, когда применение HT оказывается вредным, даже несмотря на то, что падение производительности мало.
Выводы
В заключение хотелось бы отметить, что большинство современных техник ускорения работы компьютеров так или иначе опираются на распараллеливание задач в программах. Однако, не все части программ возможно выполнять параллельно: что-то придется вычислять последовательно. В такой ситуации для оценки возможностей ускорения подходит закон Амдала. Давайте взглянем на отношение времени необходимого для последовательного выполнения задачи с помощью одного ядра процессора ко времени частично распараллеленного выполнения с помощью N ядер:
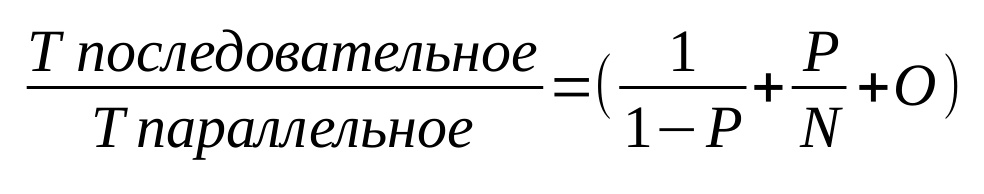
Здесь P – доля общего объема вычислений, которая может быть идеально распараллелена. N – количество используемых ядер. O – накладные расходы на применение многопоточности.
Как видим, ускорение сильно зависит от объёма задач, которые можно распараллелить, а с кодом, который должен выполняться последовательно, мы совершенно ничего не можем сделать. Таким образом, возможности многопоточности сильно ограничены.
Всё же, обычному пользователю не стоит сильно беспокоиться, так как его задачи зачастую независимы и очень хорошо распараллеливаются. Например видеоигры, одна из самых тяжелых задач обычного пользователя, успешно применяют многопоточность: пока одна часть программы составляет геометрию кадра, другая может заниматься работой искусственного интеллекта, третья обрабатывать звук, четвертая – заниматься предзагрузкой данных с диска и так далее. Здесь Hyper-Threading пользователям только на руку. Когда же речь заходит о профессиональной деятельности, Hyper-Threading может быть бесполезен, вреден или же попросту неприменим, но это уже проблемы профессионалов: Вам вряд ли придётся выполнять тонкую настройку производственного real-time оборудования, где необходим гарантированный мгновенный отклик или какого-либо другого узкоспециализированного оборудования, которое занимается непрерывными одинаковыми расчетами, как например маршрутизаторы.
P.S. Спасибо за внимание. Я попытался описать технологию максимально просто, без технических сложностей, но, если у Вас есть вопросы или какая то критика, буду рад комментариям.








Лучшие комментарии